Как написать MVC веб-фреймворк на Ruby
Привет, котятки! А давайте запилим приложение, похожее на типичное rails-приложение. Ну т.е. там будут MVC, роутинги, миграции, конфиги какие-то, всё как положено (или покладено, кому как больше нравится). Но это будет сильно-сильно упрощенная версия любимого нашего фреймворка. Не будет генераторов и интерактивной консоли, красивых лейаутов и возни с ассетами. Короче, погнали!
Rack
Начнем с того, что создадим пустую папку blog и будем в ней работать.
$ mkdir blog
$ cd blog
$ bundle init
В гемфайл пропишем:
# Gemfile
source "https://rubygems.org"
ruby '2.3.1'
gem 'rack'
Итак, я подключил репозиторий гемов, указал версию руби и мне потребуется gem 'rack'. Rack предоставляет минималистичный интерфейс между веб-приложениями. Таким образом одно веб приложение может быть встроенно в другое, а другое в третье.
Оффтопик 1. Немного предыстории про Rack
Rack уже скоро стукнет 10 лет. В те времена каждый разработчик фреймворка писал свой обработчик веб-сервера, надеясь, что пользователи смирятся с выбором автора.
Хотя, работа с HTTP достаточно проста. В конце-концов, ты получаешь запрос и выдаешь ответ. Самый общий случай обработчика работает так: на вход получает CGI-подобный запрос и в ответе возвращает три значения: http-статус, набор http-заголовков и тело ответа.
Вот пример типичного rack-приложения:
app = Proc.new do |env|
['200', {'Content-Type' => 'text/html'}, ['A barebones rack app.']]
end
Proc умеет отвечать на вызов метода call, и вернет в данном случае строку http-статуса, хеш http-заголовков и массив с контентом.
Поверх этого минимального API строятся библиотеки для поддержки типичных задач, таких как: парсинг запроса, работа с куками, удобная работа с Rack::Request(запросом) и Rack::Response(ответом) на уровне объектов, а не HTTP-протокола.
Таким образом Rack становится небольшой прослойкой между веб-сервером и нашим фактическим приложением.
- Rails использует rack в actionpack — это гем в rails, который отвечает за обработку запросов и ответов.
- Sinatra, всем известный мини DSL, для написания route-driven приложений, использует rack (см. gemspec)
- Hanami использует rack в hanami-router, геме, который отвечает за роутинги.
- Grape, rest-like фреймворк для создания API, использует rack (см. gemspec).
- Goliaph, асинхронный веб-фреймворк, используется rack (см. gemspec)
Если я не упомянул ваш любимый фрейворк, посмотрите сами. С большой долей вероятности он тоже использует Rack.
Rack. Продолжаем
Ну хорошо. Напишем тогда наше rack-приложение:
# app.rb
class App
def call(env)
[200, {}, ['Hello world']]
end
end
Всем требованиям rack-приложения отвечает. Теперь нужно сделать config.ru файл, который собственно и будет запускать наше приложение.
#config.ru
require 'rubygems'
require 'bundler'
Bundler.require
require "./app"
run App.new
Ничего особенного тут не происходит. Подключаем рубигемс, подключаем бандлер, потом Bundler.require вычитывает наш Gemfile и подключает всё что в нем лежит. Потом мы подключаем наше приложение, которое лежит здесь же рядом в корне папки, и после мы запускаем его командой run App.new.
Ну всё! Приложение готово. Давайте запустим и проверим.
$ bundle install
$ rackup
Наше приложение поднялось и мы можем посмотреть на него вживую по адресу http://localhost:9292.
Так, быстренько, одно дополнение. Давайте в качестве апп-сервер вместо webrick использовать puma. Для этого допишем в Gemfile gem 'puma' и сделаем $ bundle install. Теперь при перезапуске приложения, rackup будет использовать puma.
(Ваня, блин, что за фигня?! Почему puma? — Прим. ред.)
Отвечаю: по моему мироощущению, puma запускается и работает быстрее webrick'a. Во время разработки совершенно не важно, что вебрик однопоточный, а пума может иначе. Гораздо важнее, что вебрик подходит только для разработки, а пума и для разработки и для публикации. А значит не придется вспоминать, что нужно веб-сервер поменять. Так-то!
Router
Простецкое приложение сделали. Оно всегда отвечает одним и тем же статусом, и одним и тем же "хеловорлдом". Поехали дальше. Нам нужно, чтобы по разным URL, были доступны разные страницы. В Rails это решается через роутинги. Именно в роутингах мы прописываем соответствие урла и обработчика. Будем использовать что-то похожее и у нас. И сразу два нововведения: всё что касается нашего "фреймворка" будем складировать в папку lib, всё что касается конечного приложения — в папку app.
Сначала изобразим некое подобие конфига роутингов и я написал его в yaml'e.
#./app/routes.yml
"/" : "main#index"
"/hello": "main#hello"
"/posts": "posts#index"
Очень простое соответствие. Корневой урл ведет на MainController index-экшн. Нам нужно подключить этот конфиг в нашем приложении и я делаю это следующим образом.
# app.rb
require 'yaml'
ROUTES = YAML.load(File.read(File.join(File.dirname(__FILE__), "app", "routes.yml"))) # 1
require "./lib/router" # 2
class App
attr_reader :router
def initialize
@router = Router.new(ROUTES) # 3
end
def call(env)
result = router.resolve(env) # 4
[result.status, result.headers, result.content] # 5
end
end
Что же я тут натворил, поэтапно:
- Создаю константу ROUTES, в которую сохраняю хеш ключ-значений из нашего routes.yml файла
- Подключаю класс роутера (его еще у нас нет, но это не значит, что мы не можем о нем думать)
- Роутер создается во время инициализации приложения, получает на вход наш хеш роутингов и сохраняется в инстанс-переменную
- В момент, когда происходит вызов call в env находится вся информация о запросе, в том числе о том, какой урл был указан. Поэтому здесь мы передаем эту информацию в наш роутер, чтобы он уже решил, что с ней делать.
- Ну и в конечном результате, нам нужно соответствовать Rack-интерфейсу, а следовательно мы вернем статус, хедеры и контент.
Остается написать сам класс роутера. И вот каким он будет:
# ./lib/router.rb
class Router
attr_reader :routes
def initialize(routes)
@routes = routes # 1
end
def resolve(env)
path = env['REQUEST_PATH'] # 2
if routes.key?(path) # 3
ctrl(routes[path]).call # 4
else
Controller.new.not_found # 5
end
rescue Exception => error
puts error.message
puts error.backtrace
Controller.new.internal_error # 6
end
private def ctrl(string)
ctrl_name, action_name = string.split('#')
klass = Object.const_get "#{ctrl_name.capitalize}Controller"
klass.new(name: ctrl_name, action: action_name.to_sym)
end
end
А тут всё достаточно просто.
- Сохранили, значит, наш хеш роутингов
- Получаем путь из запроса
- Если у нас по этому пути какое-то значение имеется,
- то будем его обрабатывать, как полагается (подробно объясню ниже)
- Если нет пути, то мы ответим 404 (Not Found)
- А если случилась какая-то беда, то выведем в консольку информацию и будет отвечать 500 (Internal Server Error)
Что же происходит в пункте 4?
А вот что: мы находим в наших роутах значение по указанному урлу. Допустим, что это запрос на корень, то в наших routes.yml мы указали "/" : "main#index". А следовательно мы в качестве значения получаем "main#index".
Из этой строки нам нужно получить контроллер, но каким образом? Это делается в методе def ctrl(string).
- Сроку
stringразбиваем по знаку решетки. Получаем два значения: имя контроллера, и имя экшена("main"и"index"). - Роутинги пишет пользователь нашего а-ля фреймворка, как и контроллеры. Поэтому мы из строки собираем имя контроллера (
MainController) - иницируем его (
MainController.new(name: "main", action: :index)) - и в методе resolve делается call для этого контроллера.
Вот так быстро мы добрались до контроллеров. Продолжим?
Записаться
Хочешь узнать ещё больше?
Запишись на обучение к автору!
Оффтопик 2. Первый контроллер
О! Теперь можно создать наш первый собственный контроллер
# app/controllers/main_controller.rb
class MainController < Controller
def index
@test = "Some dump text here"
@arr = %w(one two three)
end
end
Мы не знаем, как пользователь нашей нехитрой библиотеки будет называть контроллеры. Их контроллеры будут наследоваться от нашего, но их все равно нужно подключить в наше приложение. Поэтому в app.rb допишем следующую строчку. А заодно сделаем такое же и для папки lib, чтобы не указывать отдельно, что подключить:
# app.rb
Dir[File.join(File.dirname(__FILE__), 'lib', '*.rb')].each {|file| require file }
Dir[File.join(File.dirname(__FILE__), 'app', '**', '*.rb')].each {|file| require file }
...
Controller
Так, что же нам нужно от контроллеров? Любой уважающий себя контроллер должен уметь отвечать на вызов call, знать своё имя и экшн, с которым будет вызван.
Разбирая роутинги, я забыл упомянуть о следующем: как это видно из кода в result будет возвращаться объект контроллера.
def call(env)
result = router.resolve(env)
[result.status, result.headers, result.content]
end
Помните? Вот тут роутер зарезолвил наш запрос и вернет нам в result контроллер. А дальше мы будем у него спрашивать про статус, заголовки и контент. ОК, приступим!
# ./lib/controller.rb
class Controller
attr_reader :name, :action
attr_accessor :status, :headers, :content
def initialize(name: nil, action: nil)
@name = name
@action = action # 1
end
def call
send(action) # 2
self.status = 200 # 3
self.headers = {"Content-Type" => "text/html"}
self.content = ["Hello world"]
self
end
def not_found # 4
self.status = 404
self.headers = {}
self.content = ["Nothing found"]
self
end
def internal_error # 5
self.status = 500
self.headers = {}
self.content = ["Internal error"]
self
end
end
Одна проза и никакой романтики:
- Сохраняем экшн, который будет вызван
- Собственно вызываем этот экшн
- Исключительно из-за желания упростить, но получить работающий вариант, я говорю, что все успешные вызовы у нас будут со статусом 200, хедерами на HTML, а в теле будет уже всем надоевший "Hello world".
- Сделал отдельный метод для не найдено. Вернуть мы должны именно контроллер, а не контент, поэтому
selfна конце - Такая же история и с пятисоткой.
После всех этих манипуляций, при запуске приложения и переходу во пустому урлу, мы должны увидеть Hello world. Всё работает!
Views
Еще немного доработаем напильником наш контроллер. В качестве шаблонизатора я выбрал Slim. Он очень просто прикручивается к нашему фреймворку:
# GEmfile
...
gem 'slim'
$ bundle install
Далее мы контроллере изменим наш контент:
# ./lib/controller.rb
...
def call
send(action) # 1
self.status = 200
self.headers = {"Content-Type" => "text/html"}
self.content = [template.render(self)] # 2
self
end
def template # 3
Slim::Template.new(File.join(App.root, 'app', 'views', "#{self.name}", "#{self.action}.slim"))
end
...
Пояснения:
- Наш кастомный контроллер (MainController), когда произойдет вызов call, а соответственно будет выполнен метод index, определит несколько новых инстанс-переменных. Следуя нашему примеру, появятся новые переменные
@testи@arr. - Именно для этого мы в наш шаблонизатор передаем сам инстанс контроллера. Таким образом определенные переменные в контроллере будут доступны из шаблона
- В этом методе мы создаем сам объект шаблона, подтаскиваем нашу вьюшку для конкретно этого контроллера и этого экшене (
app/views/main/index.slim)
Всё достаточно просто. Последнее, что осталось сделать, это добавить метод root в наше приложение.
# app.rb
...
class App
...
def self.root
File.dirname(__FILE__)
end
end
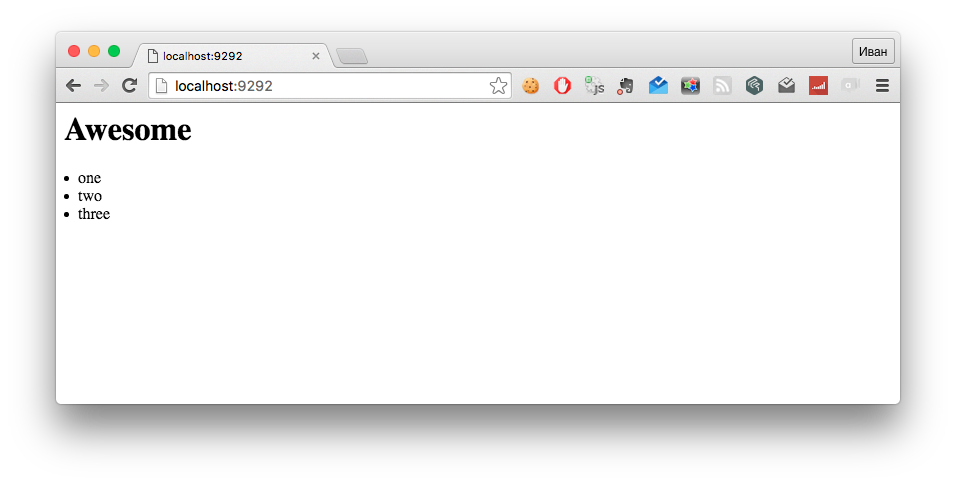
Готово! Теперь мы можем прописывать свои роуты, делать минимальные контроллеры и рисовать вьюшки. И первая вьюшка будет такой:
h1 = @test
- @arr.each do |elem|
li = elem
В результате после запуска нашего приложения мы увидим:
Model
Эй, ты еще здесь? Тебе что, интересно еще и про модели узнать?
Ну ладно, только чур, никакого ActiveRecord'a. Мы будем использовать замечательный гем, который может тоже самое и немного больше sequel и саму базу sqlite.
# Gemfile
...
gem 'sequel'
gem 'sqlite3'
Самое классное в нём, что нам не придется создавать какую-то нашу модель, от которой будут наследоваться другие модели. А потому сразу будем рассматривать на примере модели постов. В нашем routes файле уже есть запись про "/posts" => "posts#index". А потому создадим контроллер, модель и вьюшку.
# ./app/models/post.rb
class Post < Sequel::Model(DB)
end
Типичная модель в rails-приложении (только наследуется от Sequel::Model).
# ./app/controllers/posts_controller.rb
class PostsController < Controller
def index
@posts = Post.all
end
end
Типичный рельсовый контроллер, ни дать, ни взять.
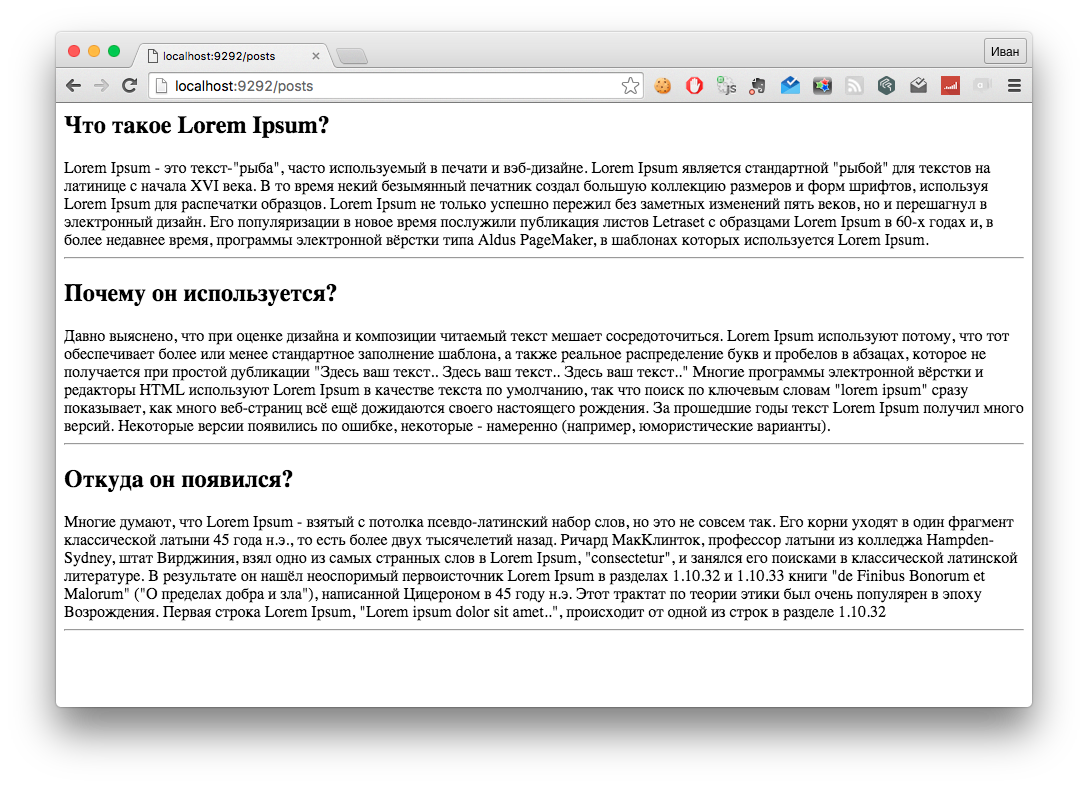
/ ./app/views/posts/index.slim
- @posts.each do |post|
h2 = post.title
div = post.content
hr
И простецкая вьюшка. А что собственно еще нужно?
А нужно вот что! Внимательный читатель увидел, что наследуем мы нашу модель от Sequel::Model(DB). А в свою очередь константа DB у нас нигде не определена. О чем и скажет приложение при попытке запуска. Более того, что это за фреймворк, если мы нигде не определили конфиги доступа к базе данных. С этого и начнём:
# app.rb
db_config_file = File.join(File.dirname(__FILE__), "app", "database.yml")
if File.exist?(db_config_file)
config = YAML.load(File.read(db_config_file))
DB = Sequel.connect(config)
end
...
Я опять дописал в app.rb небольшой кусок кода. Первая строчка проверяет есть ли файл конфига. Если есть то мы читаем файлик, парсим, создаем подключение к базе данных и сохраняем в контанту DB.
А вот как будет выглядеть конфиг в нашем случае:
# ./app/database.yml
adapter: sqlite
database: "./app/db/dev.sqlite3"
Логично, что нам нужно чтобы этот файл базы данных существовал. Выполним несколько команд.
$ mkdir -p app/db
$ touch app/db/dev.sqlite3
Узнать подробности
Автор этой статьи ведёт
обучение основам Ruby on Rails
Migrations
Осталось совсем немного. Посты у нас уже есть, но у нас нет ни таблицы, ни самих постов. Это решается не так уж сложно. Миграции будут запускаться автоматически в момент запуска приложения. Для этого нам понадобится экстеншн для Sequel'a. Добавим его одной строкой в блоке, где определяется коннект к базе данных.
# Создаем коннект к базе
db_config_file = File.join(File.dirname(__FILE__), 'app', 'database.yml')
if File.exist?(db_config_file)
config = YAML.load(File.read(db_config_file))
DB = Sequel.connect(config)
Sequel.extension :migration
end
# Подключаем все классы нашего фреймоворка
Dir[File.join(File.dirname(__FILE__), 'lib', '*.rb')].each {|file| require file }
# Подключаем все файлы нашего приложения
Dir[File.join(File.dirname(__FILE__), 'app', '**', '*.rb')].each {|file| require file }
# Если есть коннект к базе данных, то прогоняем миграции
if DB
Sequel::Migrator.run(DB, File.join(File.dirname(__FILE__), 'app', 'db', 'migrations'))
end
Стоит обратить внимание на порядок выполнения подключаемых файлов. Сначала мы проверяем, есть ли база данных и подключаемся к ней, потому что для моделей нашего приложения важно, чтобы DB-коннект был определен.
После чего мы вычитываем наш фреймворк, потому что иначе контроллеры из приложения не смогут найти к чему обратиться. Потом вычитываем папку app. Теперь определены и контроллеры и база данных.
И после всего этого мы просто выполняем команду мигратора run. Определяем, что наши миграции будут лежать в папке app/db/migrations/.
Ну и на последок напишем две миграции. Одна создаст табличку постов, другая создаст несколько постов.
# ./app/db/migrations/001_create_table_posts.rb
class CreateTablePosts < Sequel::Migration
def up
create_table :posts do
primary_key :id
column :title, :text
String :content
index :title
end
end
def down
drop_table :posts
end
end
# ./app/db/migrations/002_add_some_posts.rb
class AddSomePosts < Sequel::Migration
def up
Post.create(
title: 'Что такое Lorem Ipsum?',
content: 'Lorem Ipsum - это текст-"рыба"...'
)
Post.create(
title: 'Почему он используется?',
content: 'Давно выяснено, что при оценке дизайна...'
)
Post.create(
title: 'Откуда он появился?',
content: 'Многие думают, что Lorem Ipsum - взятый с потолка...'
)
end
def down
end
end
Запускаем наше приложение и вот что получилось:
Оффтопик 3. Наводим красоту
На самом деле, всё это подключение значительно разрослось и я решил вынести его в отдельный файлик lib/boot.rb
# ./lib/boot.rb
# Создаем коннект к базе
db_config_file = File.join(File.dirname(__FILE__), '..', 'app', 'database.yml')
if File.exist?(db_config_file)
config = YAML.load(File.read(db_config_file))
DB = Sequel.connect(config)
Sequel.extension :migration
end
# Подключаем все классы нашего фреймоворка
Dir[File.join(File.dirname(__FILE__), '..', 'lib', '*.rb')].each {|file| require file }
# Подключаем все файлы нашего приложения
Dir[File.join(File.dirname(__FILE__), '..', 'app', '**', '*.rb')].each {|file| require file }
# Если есть коннект к базе данных, то прогоняем миграции
if DB
Sequel::Migrator.run(DB, File.join(File.dirname(__FILE__), '..', 'app', 'db', 'migrations'))
end
# Читаем роутинги
ROUTES = YAML.load(File.read(File.join(File.dirname(__FILE__), '..', 'app', 'routes.yml')))
Обратите внимание, что во всех путях добавилось '..', это потому что сам boot.rb лежит в lib, а все пути раньше были относительно корня.
That's all folks!
Да, на этом всё. Как видите, написать подобное приложение не так уж и сложно. А подобные упражнения дают понимание, как же оно всё таки работает.
Не могу отпустить вас без домашнего задания. Попробуйте реализовать что-нибудь из этого списка:
- Сказать по правде — это задание с одного из моих собеседований. Так интервьюер после каждого написанного мной метода троллил меня фразами: "Может быть тестик напишем?", "А вот если бы мы были настоящими программистами, мы бы ведь это протестировали?", "Представь, что как будто наше приложение работает. Нам ведь нужны тесты?". Так что задание Раз — покрыть код тестами.
- У нас очень скудные роутинги — все запросы обрабатываются как GET. Было бы интересно посмотреть на реализацию полного RESTful приложения
- Поддержка лейаутов не была бы лишней для приложения
- Папка public могла бы отдавать ассеты, минуя создание контроллера
- Как насчет реализовать интерактивную консоль на подобии
rails c. Было бы здорово общаться с моделями через неё. - Генераторы! Миграций, моделей, контроллеров, вьюшек — генерация этих файликов любима нами с rails-младенчества.
- Ну и суперзадача для суперпрограммиста: вынести всё это дело в гем, чтобы можно было одной командой сгенерировать приложение и заняться уже только наполнением папочки
app.
Прикладываю ссылку на репозиторий с конечным вариантом. Вуаля!
Дерзайте!