Introduction to graphs and Neo4j. Graph processing in Spark.

You should refer to a graph as "your grace"
Music to listen while reading the article https://www.youtube.com/watch?v=3zegtH-acXE
Hail to the Table
Programmers automate the world. Starting with a money counting process automation, where tables are convenient, programmers put everything they could in tables. An that worked. In the last century. And this is good, since from the depths of the centuries we inherited SQL - a table query language. SQL is enough in almost all the cases - it is simple, logical and everyone knows it.
The situation in the real world is a bit more complicated. It is not so effective to store big and complex dependencies in tables in a matter of resources (a disk space, CPU, and the most important resource - time). But what data is not ideal for tables? Maybe this data is redundant?
The important graph
There is a term in math graph - a set of nodes (vertices) and relation pairs of them (edges).
A minimal graph - is two nodes and one edge between them. For example, with this minimal graph we can draw a married couple: M ---- W. I.e. graph represents natural relations between things and chains of these relations.
For example, writing set of computer folders in a table. There are nearly 5 gems for rubyists and only one correct solution - ltree + indexes. Apart from the correct solution there is an ideal one: LDAP. And what about a company's structure in a table? You can, but the idea is kinda bad, LDAP comes to the rescue again. Both of them are trees - there is a root and branches, and the thickest branch is a stem :)
Never seen a graph in my life.
Well, even my beloved git is a graph. Execute following in any of yours repositories:
git log --graph --abbrev-commit --decorate --date=relative --all
And you will see the whole tree of changes.
Another graph - is the set of family ties in Star Wars (as you remember, only Emperor there was an orphan): http://www.martingrandjean.ch/star-wars-data-visualization/
Moreover, the whole Internet stays afloat thanks to graphs. For example, Dijkstra's algorithm solves the task of finding the shortest path.
If we have a simple graph we can represent it in tables.
Graphs can be different, by the way. A graph in which dependencies are directed and there are no loops is called ... directed acyclic graph https://en.wikipedia.org/wiki/Directed_acyclic_graph. This type of graph is important to understand Spark-applications, it also helps with formalizing and optimizing business processes.
If Russian Post knew about these types of graphs, people would use their services more often and they wouldn't have a need to sell cigarettes and vodka in their offices. And if we recalled Spark, RDD is a tree of different RDD versions (if you don't know what it means, read Spark creator's publications ).
Dependencies in applications are also graphs, for example ruby-erd can draw ruby apps.
Neo4j and simple queries.
What if we have thousands of nodes? We still can use tables but we will get tired soon. Here is where a special tool comes to help - graph databases. There are lots of them, but we choose Neo4j - the simplest for the beginning and has a great web-interface with visualization. A nice picture sometimes worth thousands of words.
There are graph "databases", which store data in tables, but use graph abstraction - this kind of pornography works only in specific scenarios (and they are usually paid well, so let's remember cassandra + titan or Spark).
Let's learn Neo4j little by little with data, available for everyone.
Firstly, we launch Neo4j, which is easy, as well as everything in the Java world:
- Download archive neo4j-community-3.0.3 from their official website http://neo4j.com/
- Unpack
tar -xzvf ./neo4j-community-3.0.3-unix.tar.gz - Execute
./bin/neo4j start
Actually, don't. Stop it: ./bin/neo4j stop. Let's do it in a trndy way.
docker run --publish=7474:7474 \
--publish=7687:7687 \
--volume=$HOME/neo4j/data:/data:rw,z \
--env=NEO4J_AUTH=none neo4j:3.0
And now the most interesting, a reason why you should start with Neo4j: open it in your browser http://localhost:7474/. That's it, you are the graph database master.
Interactive console and visualization will simplify your start. And we also turned off authentication --env=NEO4J_AUTH=none. It is not needed for our experiments, but it is crucial to paranoidly turn off everything. Though it may seem funny, we need to close Docker as well :)
You also can find there a documentation about system's features and statistics of used resources.
Let's create a minimal graph.
In this article the main SQL dialect is called "Cyhper": https://neo4j.com/developer/cypher-query-language/ :-)
CREATE (c:M {id: 'Male’'})-[:rel {weight:500} ]->(b:F {id: 'Female'});
Then we look at the results:
MATCH (n) RETURN n LIMIT 1000;
![]()
Our graph is directed - even in our crazy times a man is directed to a women. Curiously enough, we may ignore the direction while searching.
MATCH p=(n)-->(b) return p
And we may not:
MATCH (n)-[p]->(b) WHERE startNode(p).id='Male' return b, n; // it will return our graph
MATCH (n)-[p]->(b) WHERE startNode(p).id='Female' return b, n; // and here it is already empty
We also may choose the strongest relationships, why should any little affairs even bother us:
MATCH (n)-[p]->(b) WHERE p.weight > 1000 return b, n /// there are no such, but to you are free to lower the filter's threshold
Notes about Cypher's queries for games at your leisure time
Let's create nodes if there are no any:
MERGE (c:M {id:'Male1'});
Let's create relations and nodes if there are no any:
MERGE (p:twivi13 {id: 'twivi13'})
MERGE (n:Real {id:'Real'})
CREATE UNIQUE (p)-[r:rel {weidth: 0}]-(n) return r
Updating relations' weight, if there are any:
MATCH (n)-[p]->(b) WHERE b.id='Male' AND n.id='Female'
SET p.weight = p.weight + 7
RETURN p
Look for the top hundred of the strongest relations in Neo4j:
MATCH (n)-[p]-(b)
RETURN p Order by p.weight DESC limit 100
Look for the nodes with more than two links:
MATCH (n) WHERE size((n)--())>2 RETURN n
And if we want to delete:
MATCH (n) DETACH DELETE n
It's cool, it works, it's easy. But no profit at all.
Creating applications with Neo4j, Spark and Twitter data
We should get another data. And the question is raised about how does an application actually interacts with Neo4j?
It supports a hipster's format HTTP API with JSON, even uploading data by packages. So it looks correct from this point of view, but for no reason at all.
The next option: protocol Bolt. Bolt is binary, can be encrypted and made specifically for Neo4j.
Every application should come up with its own protocol, because there are not enough of them.
There are already a Java driver and a Spark connector.
And since we have that freedom, we include all the trendy tools with no distinction, especially if we don't need them. And in that trendy tools we choose trendy titles: we create an application for Spark Streaming, which will read twitter, build a graph and update the graph's relations.
Spark Streaming probably will be not actual in 5 years, but is it well paid for now. And, by the way, it doesn't stream at all :)
Twitter - is an available source of a huge amount of useless data. You can even consider it as a graph of human's stupidity. But if someone tried to trace ideas' development - he/she would have an observable evidence of a classical education (which I don't have, and this article clearly shows it).
We do it in a trendy way:
Firstly, we downloand Spark sources to our local machine.
git clone https://github.com/apache/spark
git checkout branch-1.6
And in one of the examples we learn how to connect to Twitter and how to read it. And there are many other examples - it is useful to look at them to know what Spark can do.
If it is the first Twitter experience from this side, you can get keys and tokens here: https://apps.twitter.com. After the example's modification we get something like this:
package org.apache.spark.examples.streaming
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.SparkContext._
import org.apache.spark.streaming.twitter._
// yes, sure, Eclipse would refactor this all, but I'm on Vim
import org.apache.spark.streaming.twitter.TwitterUtils
import org.apache.spark.storage.StorageLevel
import org.apache.spark.SparkConf
import org.neo4j.driver.v1._
object Twittoneo {
def main(args: Array[String]) {
StreamingExamples.setStreamingLogLevels()
// and here I firstly put the keys:)
System.setProperty("twitter4j.oauth.consumerKey", "tFwPvX5s")
System.setProperty("twitter4j.oauth.consumerSecret", "KQvGuGColS12k6Mer45jnsxI")
System.setProperty("twitter4j.oauth.accessToken", "113404896-O323jjsnI6mi2o6radP")
System.setProperty("twitter4j.oauth.accessTokenSecret", "pkyl20ZjhtbtMnX")
val sparkConf = new SparkConf().setAppName("Twitter2Neo4j")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val stream = TwitterUtils.createStream(ssc, None)
val actData = stream.map(status => {
// extract from twitter json only interesting fields
val author:String = status.getUser.getScreenName.replaceAll("_", "UNDERSCORE")
val ments:Array[String] = status.getUserMentionEntities.map(x => {
x.getScreenName.replaceAll("_", "UNDERSCORE")
})
(author, ments)
})
actData.foreachRDD(rdd => {
if(!rdd.isEmpty()) {
println("Open connection to Neo4jdb")
val driver = GraphDatabase.driver( "bolt://localhost",
AuthTokens.basic( "neo4j", "neo4j" ))
try{
// collect called for execute all logic on driver
// http://spark.apache.org/docs/latest/cluster-overview.html
rdd.collect().foreach(x =>{
x._2.foreach( target =>{
val session = driver.session()
// create relation if not exist
// merge (p:twivi13 {id: 'twivi13'})
// merge (n:Real {id:'Real'})
// create unique (p)-[r:rel {weidth: 0}]-(n) return r
//
// pregix 'twi' and replacement _ to UNDESCORE require because Neo4j has many restrictions for label
val relation = "MERGE (p:twi"+ x._1+" {id:'twi"+x._1+"'}) MERGE (d:twi"+ target+" {id: 'twi" + target + "'}) CREATE UNIQUE (p)-[r:rel {weight: 0}]-(d) RETURN 1"
println(relation)
val result1 = session.run(relation)
result1.consume().counters().nodesCreated();
session.close()
})
})
} finally {
driver.close()
println("Close Neo4j connection")
}
driver.close()
}
})
ssc.start()
ssc.awaitTermination()
}
}
Take a careful look - we don't need neo4j-spark-connector for now, we take neo4j-java-driver instead of it, which is responsible only for the interaction between the java-application and Neo4j, with no converting to native RDD or GraphFrame formats. But in the next article we will need them for the real, proudly called job, Big Data engineer.
Compile and install a neo4-java library in a local Maven repository:
git clone git@github.com:neo4j/neo4j-java-driver.git
cd neo4j-java-driver
mvn clean package install
Put our code in src/main/scala/org/apache/spark/examples/streaming/Twitter2neo4j.scala. While in examples folder, add to ./pom.xml:
<dependency>
<groupId>org.neo4j.driver</groupId>
<artifactId>neo4j-java-driver</artifactId>
<version>1.1-SNAPSHOT</version>
</dependency>
Then compile the examples with ours: execute mvn -Phadoop-2.6 -Dhadoop.version=2.6.0 -DskipTests clean package.
We get a jar file with which we will work later. We will use trendy Docker instead of Spark for the compiling.
Note the Spark version - 1.6.1. It is important for your package and Spark to be the same version, because Spark evolves really fast, sometimes even too fast.
Remember the security__. Another one interesting Docker thing - we don't know who made the image, and docker works from root (made by hipsters, what can you even expect of them). Theoretically, this is a huge hole in the security. I myself work freely - with the latest Fedora and seLinux turned on, limiting the holey Docker. But no mercy for Ubuntu users. By the way, super cool and trendy Docker version is called chroot.
Let's execute a container (box, bucket), exporting current folder into /shared with read-only access (ro) and remarking seLinux context into svirt_sandbox_file_t.
SELinux context will stay even after the container stops. We also export the compiled library for neo4j-java-driver.
And had we our own central repository, for example Nexus - it would be easier.
Or, as a possible option, we can edit pom.xml and compile with all the needed dependencies. We will get two containers which should interact with each other, so we choose a path of least resistance - Spark container will use Neo4j network stack, sharing its ip address with it.
For that we execute docker ps | grep -i neo4j | awk '{print $1}' and look at the container id.
docker run -it -v `pwd`:/shared:ro,z \
-v /path/to/neo4j-java-driver/driver/target:/neo4jadapter:ro,z \
--net=container:ca294ee9e614 \
sequenceiq/spark:1.6.0 bash
We are in the container. We have hadoop and Spark. But we don't touch hadoop - it doesn't disturb us, we launch Spark so it runs locally (--master local[4]):
spark-submit --jars /neo4jadapter/neo4j-java-driver-1.1-SNAPSHOT.jar \
--packages "org.apache.spark:spark-streaming-twitter_2.10:1.6.1" \
--class org.apache.spark.examples.streaming.Twittoneo \
--master local[4] \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 1 \
--verbous \
/shared/target/spark-examples_2.10-1.6.1.jar
Wait at least 10 minutes and observe the result. The more data we gather, the more interesting it is going to be.
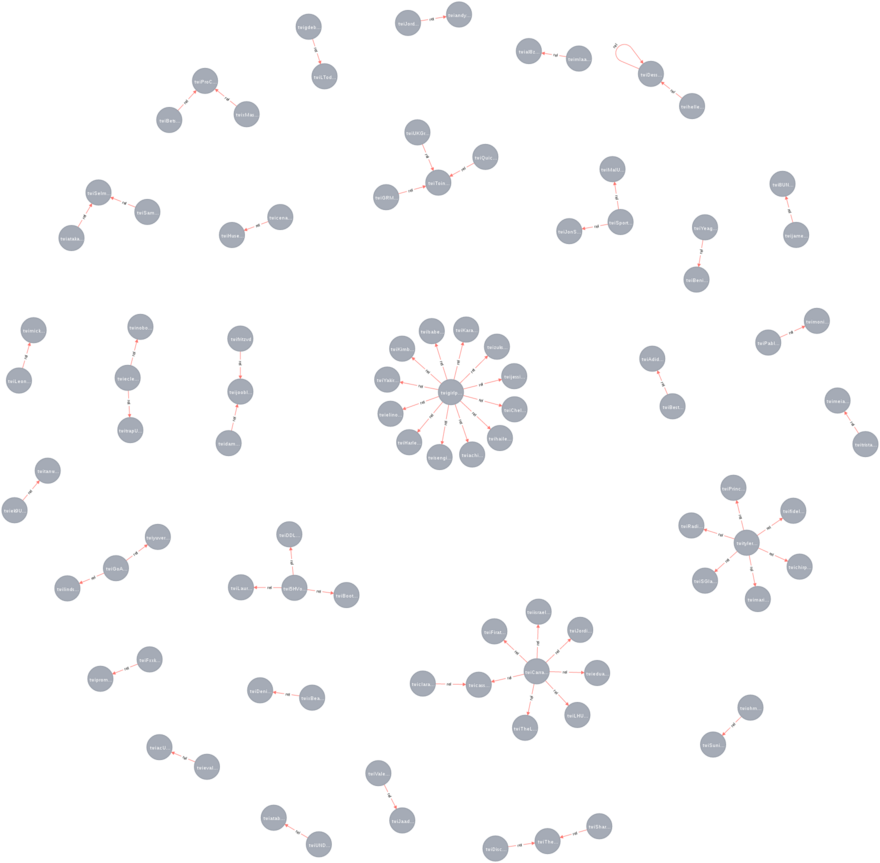
Incredible!!!
If you want it to be more beautiful, more dynamic and even in a real-time way, we have a course on mkdev Ekaterina Shpak course. It teaches d3.js and other tricks of a lovely frontend. The Big Data, mostly, is about presenting your achievements to an average manager, who though has a classical education, will not understand a thing without a picture.
There is one important moment - the Spark superpower isn't used. We, after all, can make ready-made graph in it, aggregate all the messages and only after that put them in Neo4j. You can significantly increase an amount of information treated by the system. But who cares about it in a learning example. Even in real world few people care :)
Conclusions and forecasts for the next part
The database we got and the selection we make is not practical. The next step is, for example, to find the most authoritative users (find them, give them money and let them advertise our products). Or trace your brand's mentions, and, depending on the situation (do they criticize or commend you, who respond), try to increase income. These are obvious examples of usage, but in our dear Germany they have the law which prohibits keeping users data, which can clearly identify them.
In other words, by using a big amount of data one can find a user with indirect evidences. So the fact that I am paranoid doesn't exclude a possibility for the surveillance. And it is much nicer to be the one who observes, than the one who is observed. Graphs help a lot, and we will talk about it in the next part. By the way - we may as well look at solutions, in which Neo4j is not enough. With all its value it is not scalable after all. Neo4j authors disagree with that, but who even believes them.
By the way, a peculiarity of all nosql solutions - a database's structure depends on your queries. When some complain that something is schemaless - they either lie or it is made poorly :)