How networks work, part two: teaming for fault tolerance, bandwidth management with Traffic Control, tap interfaces and Linux Bridge

In the article How networks work: what is a switch, router, DNS, DHCP, NAT, VPN and a dozen of other useful things we presented the core components of networks. You need to read it before you start with this one.
In this article we’re going to talk about how to configure network teaming in Linux. You need to do that in virtual environment with the use of libvirt, which we discussed in Virtualization basics and an introduction to KVM.
DevOps consulting: DevOps is a cultural and technological journey. We'll be thrilled to be your guides on any part of this journey. About consulting
But this time we’re not gonna rely blindly on libvirt. We’ll try to realize what lies beyond a couple of lines of simple XML-file, which describes a virtual environment or networks. Thus, we’ll find out about how Linux Bridge, tap interfaces and Linux Traffic Control work and what you need them for as well as virtualization using these tools.
Let’s talk about what teaming is, for starters.
What do you need teaming, bonding, link aggregation and port trunking for?
Let’s not dig too much into differences in implementation and sets of features, that’s not the point here. Basically teaming, bonding, link aggregation and port trunking mean the same thing. It is combining several physical interfaces into a logical one, which allows increasing bandwidth and/or ensuring fault tolerance.
We’re gonna call it 'teaming’, as this term is used in the modern Linux distributions.
Besides teaming, there is also bonding, which was replaced by teaming. If you want to know the differences between these two in Linux you can read Red Hat documentation According to this table, there’s no point in using teaming in new distributions, but I may be wrong. If you’re curious enough, you might as well read bonding documentation. Who knows, maybe one day you’ll have to work with it. We’re not going to go into a bunch of unnecessary details about how exactly teaming works. Do you really need to know that teaming is basically a small swift driver in Linux kernel and a set of custom APIs for more flexibility and extensibility? You probably don’t. But if you ever will, there’s a magnificent list of links down below with, among other things, the description of Linux teaming infrastructure.
Let’s now discuss what ‘increasing bandwidth’ and ‘ensuring fault tolerance’ mean.
Let’s say that the server has only one NIC. If it gets fried, the server will have no connection to the Internet. But if there were two NICs with two different IP addresses, the server would identify them as two separate NICs with two different IP addresses. Which means that the same connection would have information only about one interface. If only one got fried, all the connections going through broken NIC would be lost completely.
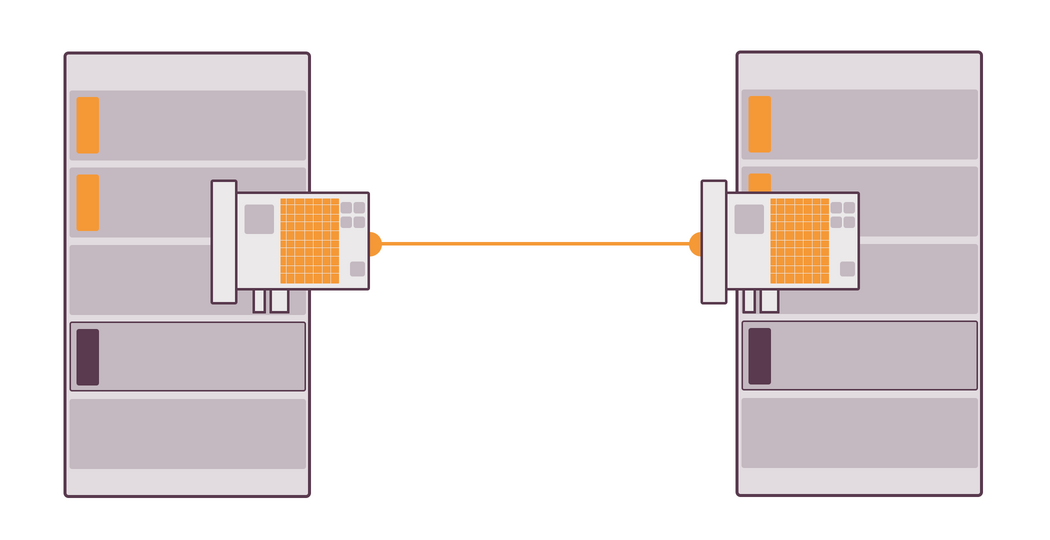
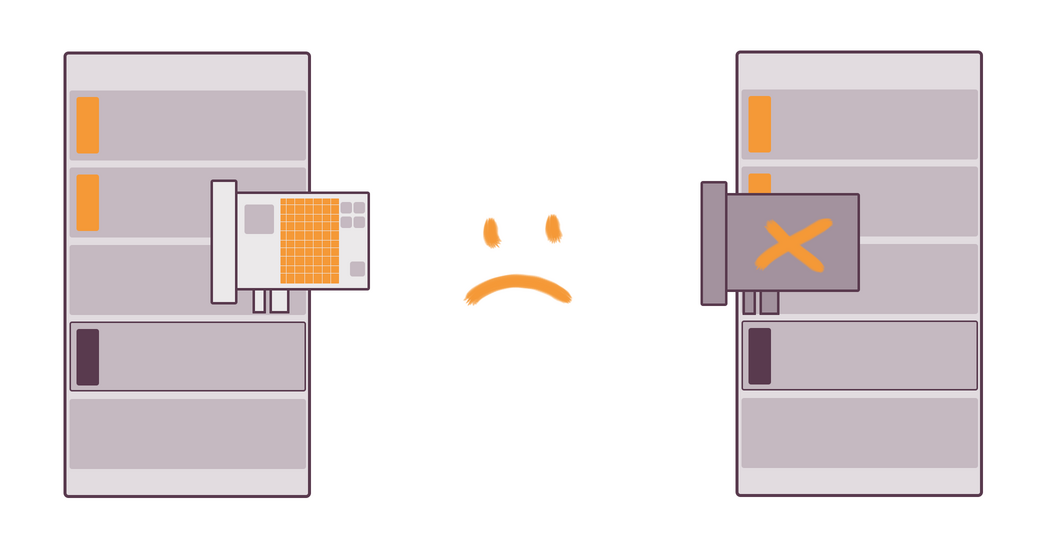
If you use teaming, both NICs are hidden behind the same programming interface, for which teaming is responsible for. If one of NICs gets fried or is disconnected from the server, the connection won’t be lost, as the traffic will be automatically routed through the other NIC. That’s all you need to know about fault tolerance.
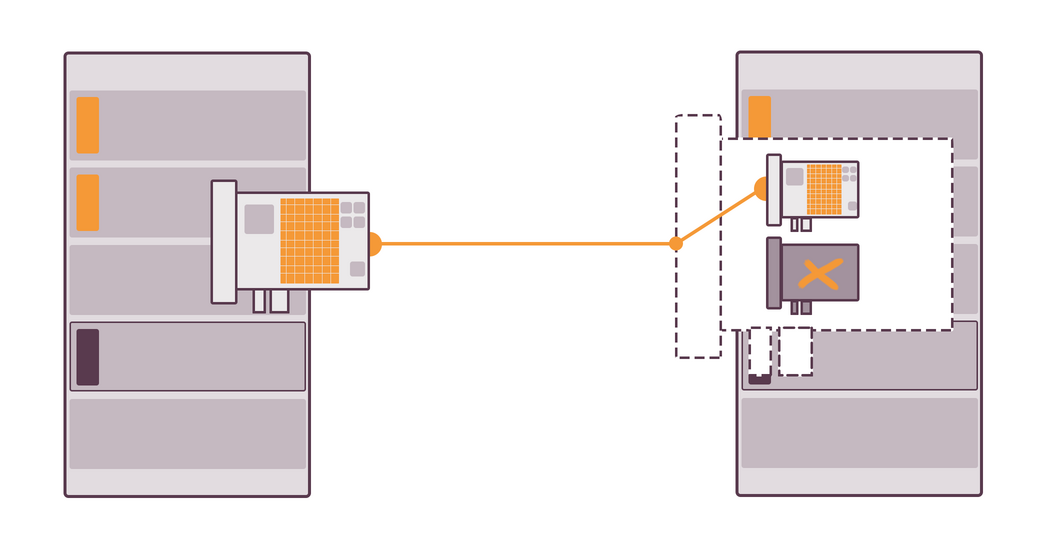
For instance, we have a server with tons of files, which are available for anyone from local network to download. If two NICs are connected to this file server and some two other servers try to download files at the same time, each is going to get a half of the bandwidth. However, if there are two NICs combined together with the help of teaming on this file server, each server will get the maximum available for one NIC download speed.
Getting real
Let us digress for a moment and make some things clear, that’s highly important.
First of all, if a server with one NIC tries to download something from a server with two NICs, the speed will not be doubled, as the bandwidth of the recipient server is limited by the NIC. You can change it by putting two NICs into both severs.
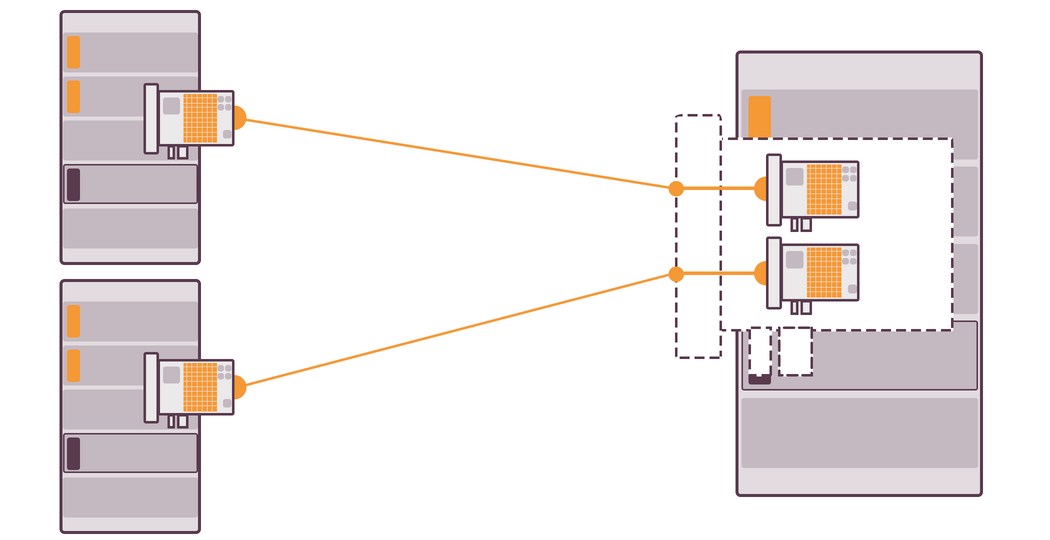
Secondly, if you connect two NICs to the server and try to download a large file, the speed will not be doubled only because there is another NIC. It might increase a little, though. However, it’s really convenient when you download several files simultaneously. You’ll get the traffic you wanted and all the files will be downloaded at the maximum for each NIC speed.
Thirdly, having teaming doesn’t necessarily mean having no fault tolerance problems. Let’s keep in mind that NICs are connected to a router (or a switch, or a bridge, or a hub.) This means that if some of them die, even five NICs will not prevent us from network being down. So we also need a fault-tolerant router (as well as a switch, a bridge or a hub.)
Checking if teaming is working properly
Well, now you know what teaming is for. It might be troublesome to check its work in a real environment as you need a lot of hardware and wires. I only have a laptop with one NIC around, which means that I need virtualization to test everything out. Let me remind you that it would come in handy to read our article about it. It’ll help you not only come to grips with the topic but also set up a local environment for future work with libvirt + KVM.
Powering on a CentOS virtual machine with libvirt
Download Centos ISO with KVM support
Download a Kickstart file
In the very end of the file change PUBLIC_KEY to your public SSH key.
Power on a new virtual machine via a SHH command (don’t forget to update a Kickstart file path and a CentOS image one):
sudo virt-install —name teaming —ram 2048 —disk size=8,format=qcow2 —vcpus 2 \
—location /tmp/CentOS-7-x86_64-Minimal-1708.iso \
—initrd-inject /path/to/ centos-cfg-minimal.ks \
—virt-type kvm \
—extra-args ks=file:/ centos-cfg-minimal.ks
Disc and RAM sizes are up to you.
Search for an IP address via sudo virsh net-dhcp-leases default and try to login via SSH as a root user. Did it work? Then let’s continue.
Playing around with Linux Bridge
All things managed by libvirt such as virtual machines, networks and file repositories are described in XML files. When you update these files, you need to update all of the above. You might, for example, change the network interface configuration of your virtual machine.
Open an XML file of the virtual machine:
virsh edit teaming
Then find here a network interface definition:
...
<interface type='network'>
<mac address='52:54:00:95:3f:7b'/>
<source network='default'/>
<model type='virtio'/>
<address type='pci' domain='0x0000' bus='0x00' slot='0x03' function='0x0'/>
</interface>
...
Here you can see which network this interface is connected to (or rather, to the switch of which network) — <source network='default'/> as well as look at and change a MAC address of the interface and some other settings.
You need to make sure this particular interface (which libvirt network consists of) is connected to a virtual switch. You can also have a look at an XML network definition, if you need to know which switch is being used for the network:
virsh net-dumpxml default
The result:
<network connections='1'>
<name>default</name>
<uuid>c6d5c8b9-3dbe-4be5-9ef9-25afce83e699</uuid>
<forward mode='nat'>
<nat>
<port start='1024' end='65535'/>
</nat>
</forward>
<bridge name='virbr0' stp='on' delay='0'/>
<mac address='52:54:00:7e:33:23'/>
<ip address='192.168.122.1' netmask='255.255.255.0'>
<dhcp>
<range start='192.168.122.2' end='192.168.122.254'/>
</dhcp>
</ip>
</network>
The switch definition: <bridge name='virbr0' stp='on' delay='0'/>.
Now you know that its name is virbr0. Let’s see which interfaces are connected to it using brctl:
brctl show virbr0
bridge name bridge id STP enabled interfaces
virbr0 8000.5254007e3323 yes virbr0-nic
vnet0
There are two interfaces, one belongs to the host and the other to your virtual machine (vnet0). The host interface has an IP address inside the libvirt network (192.168.122.1/24). The virtual machine traffic goes through this interface. You can see it for yourself if you fiddle around with ip r and ip addr on the host and inside the virtual machine as well as examine the result of traceroute to the neighboring virtual machine or to mkdev.me.
Let’s now see what MAC addresses the connected interfaces have:
brctl showmacs virbr0
port no mac addr is local? ageing timer
1 52:54:00:7e:33:23 yes 0.00
1 52:54:00:7e:33:23 yes 0.00
2 52:54:00:95:3f:7b no 126.91
2 fe:54:00:95:3f:7b yes 0.00
2 fe:54:00:95:3f:7b yes 0.00
The result might seem confusing. Why is the MAC address of an NIC host shown twice, but the one of a virtual machine NIC thrice? Why does the address of a virtual machine NIC starts with ‘52’ in one case, but with ‘fe’ in others? Why is ‘is local’ equals ‘no’ and you can see some ‘ageing timer’? Let’s see why.
First of all, we need to understand why MAC addresses are doubled. You need another Linux bridge utility for that, which is called bridge. It’ll help us to examine Forwarding Database (fdb). It is, basically speaking, a routing table used by Layer 2 devices. We usually have to do with routing at Layer 3, which is, to make it clear, an IP addresses layer. But a switch is usually a Layer 2 device and operates with MAC addresses. Let’s have a look at fdb for virbr0 bridge:
bridge fdb show br virbr0
01:00:5e:00:00:01 dev virbr0 self permanent
01:00:5e:00:00:fb dev virbr0 self permanent
52:54:00:7e:33:23 dev virbr0-nic vlan 1 master virbr0 permanent
52:54:00:7e:33:23 dev virbr0-nic master virbr0 permanent
fe:54:00:95:3f:7b dev vnet3 vlan 1 master virbr0 permanent
52:54:00:95:3f:7b dev vnet3 master virbr0
fe:54:00:95:3f:7b dev vnet3 master virbr0 permanent
33:33:00:00:00:01 dev vnet3 self permanent
01:00:5e:00:00:01 dev vnet3 self permanent
33:33:ff:95:3f:7b dev vnet3 self permanent
33:33:00:00:00:fb dev vnet3 self permanent
Let’s ignore 01:00:5e:00:00:01, 01:00:5e:00:00:fb as well as all the lines starting with 33:33. We’re going to publish an article about IPv6 and its difference from IPv4 later, which will help you understand why you need all those recurring lines. Let’s pretend for now that they don’t exist:
52:54:00:7e:33:23 dev virbr0-nic vlan 1 master virbr0 permanent
52:54:00:7e:33:23 dev virbr0-nic master virbr0 permanent
fe:54:00:95:3f:7b dev vnet3 vlan 1 master virbr0 permanent
52:54:00:95:3f:7b dev vnet3 master virbr0
fe:54:00:95:3f:7b dev vnet3 master virbr0 permanent
You also need to discard the lines responsible for the switch itself, but keep the ones relevant for your virtual machine:
52:54:00:95:3f:7b dev vnet3 master virbr0
fe:54:00:95:3f:7b dev vnet3 vlan 1 master virbr0 permanent
fe:54:00:95:3f:7b dev vnet3 master virbr0 permanent
Linux Bridge (and not only) has an option of dynamic adding of the entries into fdb, which allows it learn using the incoming traffic. Did you get the frames from the MAC address 52:54:00:95:3f:7b? Let’s automatically add it, it seems as if it’s been connected to the switch. If it remains silent for some time, we detach it in the same manner. This is what columns ‘is local?’ and ‘ageing’ mean. The first one shows if the connection to the interface is static (~= the interface is directly connected to the switch), the second shows the time since the last contact with the interface.
The bridge fdb command doesn’t show ageing, but we can see the route added automatically:
52:54:00:95:3f:7b dev vnet3 master virbr0
If network interfaces are static, ageing doesn’t make any sense, as the switch can always see that they are connected. Libvirt (but actually, qemu) is in charge of connecting the interfaces of the virtual machine to the switch, which makes dynamic routing meaningless as the switch knows everything it should about such connections. So we can turn off learning completely:
brctl setageing virbr0 0
Now we have only two virtual interface entries:
port no mac addr is local? ageing timer
1 52:54:00:7e:33:23 yes 0.00
1 52:54:00:7e:33:23 yes 0.00
2 fe:54:00:95:3f:7b yes 0.00
2 fe:54:00:95:3f:7b yes 0.00
If you were focused enough while reading, you might have noticed that the virtual machine MAC address and the one belonging to the switch are different and now you’re dying to found out the answer.
How do we make sure that libvirt uses QEMU for sure? Go to
/var/log/libvirt/qemu, look for a log with a name of your virtual machine name and find this.
Tap interfaces
If you find an NIC MAC address in a virtual machine, you can see 52:54:00:95:3f:7b, while in brctl showmacs you see fe:54:00:95:3f:7b. The only difference here is that fe instead of
52. The thing is that libvirt creates a tap interface on host for every virtual machine.
Tap interface is a Linux virtual kernel-based interface. Instead of receiving and sending packets via some physical media, tap interface receives and sends them from and to the user space program.
To put it simply, it is some sort of a file descriptor, to which Linux Bridge sends Ethernet Frames. QEMU reads them from the descriptor and sends to the virtual machine.
Do you know what a file descriptor is? Don’t worry if you don’t. We’ll talk about it in the next article some day. Sign up for our newsletter below to be the first to know.
For the virtual machine it is as if all the frames arrived to the physical interface with a 52:54:00:95:3f:7b MAC address. What’s important is that the tap interface is just a virtualization of a network interface, and the virtual machine doesn’t know anything about it, it still recognizes it as a full-fledged physical interface.
That’s not a big deal for now when and how exactly tap interface is created. We have libvirt which hides all the unnecessary details until we really want to know how everything works. However, let’s run a couple of commands on host for us to know where to dig in for the future.
Firstly, let’s look at the full virtual machine configuration. When you used virsh edit for that, the configuration was always static. But when the machine is on, configuration might differ a little, as libvirt does a bunch of useful stuff, such as creating of a tap interface and connecting it to a virtual machine. So let’s see now the configuration of a powered-on virtual machine interface.
virsh dumpxml teaming
...
<interface type='network'>
<mac address='52:54:00:95:3f:7b'/>
<source network='default' bridge='virbr0'/>
<target dev='vnet0'/>
<model type='virtio'/>
<alias name='net0'/>
<address type='pci' domain='0x0000' bus='0x00' slot='0x03' function='0x0'/>
</interface>
...
See your tap interface here: <target dev='vnet0' />. Tap interfaces exist on host and you can see the list of them with ip tuntap:
virbr0-nic: tap UNKNOWN_FLAGS:800
vnet0: tap vnet_hdr
Since it is a full-fledged, if virtual, interface, you can see it on the host interface list:
ip link
11: virbr0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 52:54:00:7e:33:23 brd ff:ff:ff:ff:ff:ff
12: virbr0-nic: <BROADCAST,MULTICAST> mtu 1500 qdisc fq_codel master virbr0 state DOWN mode DEFAULT group default qlen 1000
link/ether 52:54:00:7e:33:23 brd ff:ff:ff:ff:ff:ff
62: vnet0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master virbr0 state UNKNOWN mode DEFAULT group default qlen 1000
link/ether fe:54:00:95:3f:7b brd ff:ff:ff:ff:ff:ff
At the end of the article you can find some links to the sources where you can read about tap and tun more. Tun is pretty similar to tap, but on Layer 3, not 2.
How to limit Internet speed with libvirt?
That would be pretty easy to demonstrate the fault tolerance of a server with teaming which have already been configured. But how can you demonstrate increased bandwidth?
Let’s edit the XML virtual machine configuration file: virsh edit teaming, find the virtual interface definition and add there <bandwidth>:
<interface type='network'>
<mac address='52:54:00:95:3f:7b'/>
<source network='default'/>
<model type='virtio'/>
<address type='pci' domain='0x0000' bus='0x00' slot='0x03' function='0x0'/>
<bandwidth>
<inbound average='128'/>
<outbound average='128'/>
</bandwidth>
</interface>
Now the connection speed is limited to 128 kbps. We can set the download speed and other stuff using the parameters of incoming and outgoing connections. You can read about all the available options in libvirt docs. Now let’s see if the limitation actually works. Let’s restart the virtual machine:
virsh destroy teaming && virsh start teaming
Login via SSH and try downloading some file using, for example, wget:
wget http://centos.schlundtech.de/7/isos/x86_64/CentOS-7-x86_64-Minimal-1708.iso
If you look at the download speed, you can see that it is truly limited. Well, how does it work?
What is Linux Traffic Control?
Traffic control allows managing and transmission of packets going through NICs. You can set the processing speed of the packet queues, filter the packets or dispose of them if they don’t meet your requirements. If desired, you can set fixed speed for SSH connection for ever, even if you download large files via the same interface. As you can see, there’s everything you need to work with network packets. When there’s a will, there’s a way.
Quality of Service (QoS) is a synonym to the Traffic Control.
As many other good things in life, packets management in the Linux kernel is implemented through the packet scheduler. There’s a tc utility for you to adjust its work. Linux Traffic Control is a highly flexible, full-fledged and powerful thing. We’ll try to talk about the basics of the traffic control as well as how libvirt configures them.
The traffic control is based on good old queues, the process is controlled by Queueing Disciplines (qdisc). Each network interface has one default queue that doesn’t follow any rules, the packets are put into the queue and then extracted as soon as possible. If the network doesn’t work properly, the packets might be left in a queue so the the data wouldn’t be lost during transmission.
Is qdisc a queue? After some research we can say that terms "queue" and "qdisc" are interchangeable. They are both based on a queue as a data structure, while qdisc is basically a list of rules to process such queues.
But FIFO queue wouldn’t do any good by itself. That’s why Linux allows you to construct complex trees of queues, which follow different rules of queue processing, for different ports and from diverse sources.
There are two types of qdiscs: classless and classful. Classless ones just transmit the traffic updating it at the same time (for example, adding hold-queue). Classful ones include another queues and classes and usually filter the packets and distribute them to several queues.
Don’t you worry if what you see below is not entirely clear to you. Look through all the information about Linux Traffic Control at the end of the article and then go back to read this one. It should become clearer.
What you need to pay your attention to now is the connection between <bandwith> in the virtual interface definition and the traffic control configuration on host. As we’ve mentioned before, the tc utility is responsible for that. Using it you can see what exactly was configured by libvirt:
tc qdisc show dev vnet0
qdisc htb 1: root refcnt 2 r2q 10 default 1 direct_packets_stat 0 direct_qlen 1000
qdisc sfq 2: parent 1:1 limit 127p quantum 1514b depth 127 divisor 1024 perturb 10sec
qdisc ingress ffff: parent ffff:fff1 ————————
Your tap interface has three qdiscs. Each interface has two ‘fake’ qdiscs — root and ingress. We call them fake because they do nothing and exist only as elements to which other qdiscs can connect.
That being said, you cannot connect to ingress anything besides packet filtering and optional packet rejection. It works this way because as we don’t have real control over the incoming data and we cannot change the speed of the incoming traffic. This is why we cannot prevent DDoS attacks completely as well. All we can do is block the traffic as fast as possible or pinpoint it to process later. This is what ingress qdisc does, which is situated in the very beginning of the incoming traffic processing. We haven’t added any incoming traffic filtering, so ingress qdisc looks rather bland.
The other two qdiscs are connected to each other. qdisc htb 1: is a top of a tree, with root as its parent. Below there’s qdisc sfq 2:, you can see it at parent 1:1. htb and
sfq are different types of queues built-in in Linux. Open the links and you’ll see the pictures that explain how they work. In a nutshell, htb allows limiting the traffic speed, while sfq tries to evenly redistribute outgoing packets. htb is a classful qdisc and sfq is a classless one(man tc can prove that).
Let’s now have a look at classes:
tc -g class show dev vnet0
+—-(1:1) htb prio 0 rate 1024Kbit ceil 1024Kbit burst 1599b cburst 1599b
Here’s our speed limiter. We can see 1024Kbit we longed for.
Well, libvirt hid once more the part of Linux which is highly useful as well as difficult. It allowed us to configure Linux packet scheduler for the virtual machine tap interface in just several clear XML lines.
Adding the second interface
Let’s move on to teaming. To do that you need the second interface, which is easy to add using virsh:
virsh attach-interface teaming network default —persistent
You can make sure that the first interface still exists either by looking at the virtual machine XML file or running ip addr there. You can also run the same command on host with the new tap interface. DHCP server even kindly assigned an IP address to our new interface, but we don’t actually need it.
Time for teaming configuration!
Setting up and configuring teaming
Login via SSH (or Spice) to the virtual machine and disable one of the connections:
nmcli con
NAME UUID TYPE DEVICE
Wired connection 1 31e82585-4c0c-4a30-ba4c-622d66a48e68 802-3-ethernet ens9
eth0 b21fbb15-ae30-4a65-9ec3-37a6b202ab5d 802-3-ethernet eth0
nmcli con delete 'Wired connection 1'
If you login to the virtual machine via SSH through the interface IP address whose connection you disabled, you’ll have to login again since teaming hasn’t been configured yet.
Install teamd: yum install teamd NetworkManager-team -y. Load the module: modprobe team. Make sure everything’s fine: lsmod | grep team.
After installing the NetworkManager-team we got an error message
Error: Could not create NMClient object: GDBus.Error:org.freedesktop.DBus.Error.UnknownMethod: Method "GetManagedObjects" with signature "" on interface "org.freedesktop.DBus.ObjectManager" doesn't exist. Rebooting solved > the issue.
There are several ways how to configure teaming:
- Manually editing of the network-scripts
- Using
nmcli - Using
nmtui
With the first two you’ll have to memorize command sequences, while the text interface might allow you to do everything fast and easy. But if you do that singlehandedly, that’ll be fast and easy too, so let’s talk about how to do everything using nmcli:
$> nmcli con add type team ifname team0 con-name team0
Connection 'team0' (e6d71407-0c9f-4871-b6d4-60f62124809e) successfully added.
$> nmcli con add type team-slave ifname ens9 con-name team0-slave0 master team0
Connection 'team0-slave0' (b8dbe2f1-7d93-4c86-9c62-8470d44e1caf) successfully added.
Now we have the team interface with a real interface and an IP address. Now, if you’ve logged in via SSH before, log out and log in again using an IP address of a team interface. Otherwise you’ll lose the connection while running this command:
nmcli con delete eth0
You also need to delete all the configured connections from the interfaces you plan to team. Add the second interface:
nmcli con add type team-slave ifname eth0 con-name team0-slave1 master team0
Connection 'team0-slave1' (d11ba15b-d13d-4605-b958-fe6d093d4417) successfully added.
Let’s look at the new interface and its address usingip addr:
ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens9: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast master team0 state UP qlen 1000
link/ether 52:54:00:54:f4:75 brd ff:ff:ff:ff:ff:ff
3: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast master team0 state UP qlen 1000
link/ether 52:54:00:54:f4:75 brd ff:ff:ff:ff:ff:ff
4: team0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP qlen 1000
link/ether 52:54:00:54:f4:75 brd ff:ff:ff:ff:ff:ff
inet 192.168.122.71/16 brd 192.168.255.255 scope global dynamic team0
valid_lft 2859sec preferred_lft 2859sec
inet6 fe80::d865:f90b:50c3:e3d0/64 scope link
valid_lft forever preferred_lft forever
team0 is shown as any other interface, it has an IP address, a MAC address and even its own qdisc. We’ve already talked about the Traffic
Control, so the lines like qdisc pfifo_fast and qlen 1000 should be familiar for you. You also need to pay attention to the fact that all three interfaces now have the same MAC address by default. If you don’t like it, you can always change it.
Let’s now play around a little with the team configurations. Teaming support several modes of working called runners. The simplest is roundrobin. As you can see from its name, all the interfaces where the packets are transmitted to will be processed in circular order. Another example is, activebackup , it uses only one interface and if it stops working, the traffic will be routed through the next available one. If you need to know all available choices, you need man teamd.conf. Let’s try activebackup.
The aim here is to configure activebackup with the new interface as the main one and theslow one (its speed was limited with tc) as a backup one. After that you need to start downloading a large file in the virtual machine and disconnect the new fast interface from the server.
nmcli con edit team0
nmcli> describe team.config
The last command will show the examples of team.config usage:
Examples: set team.config { "device": "team0", "runner": {"name": "roundrobin"}, "ports": {"eth1": {}, "eth2": {}} }
set team.config /etc/my-team.conf
If you use man and other available in Linux tools wisely, you’ll save yourself the trouble of googling everything. You can just search through the local documentation and find highly detailed descriptions with lots of examples! Another example of configuration you can find in man teamd.conf:
{
"device": "team0",
"runner": {"name": "activebackup"},
"link_watch": {"name": "ethtool"},
"ports": {
"eth1": {
"prio": -10,
"sticky": true
},
"eth2": {
"prio": 100
}
}
}
Create a teaming-demo.conf file with similar but updated for our interfaces entries:
{
"device": "team0",
"runner": {"name": "activebackup"},
"link_watch": {"name": "ethtool"},
"ports": {
"ens9": {
"prio": 100
},
"eth0": {
"prio": 10
}
}
}
Here we set an activebackup mode and make ens9 interface (the fastest) our primary one. Let’s load the configuration:
nmcli con mod team0 team.config ./teaming-demo.conf
You need o make sure that all the configurations were applied with teamdctl team0 state:
teamdctl team0 state
setup:
runner: roundrobin
ports:
ens9
link watches:
link summary: up
instance[link_watch_0]:
name: ethtool
link: up
down count: 0
eth0
link watches:
link summary: up
instance[link_watch_0]:
name: ethtool
link: up
down count: 0
Oops, they haven’t yet! The thing is that the config can be loaded only during creating of a team interface. You can use this fact to make sure that our configurations can survive the reboot, so let’s reload our virtual machine. If everything’s okay, you can login via SSH, run teamdctl team0 state and see this:
setup:
runner: activebackup
ports:
ens9
link watches:
link summary: up
instance[link_watch_0]:
name: ethtool
link: up
down count: 0
eth0
link watches:
link summary: up
instance[link_watch_0]:
name: ethtool
link: up
down count: 0
runner:
active port: ens9
Time to disconnect the interface!
Checking the teaming’s work
In this video we log on to the virtual machine and start downloading a file in a separate session and then disconnect the main interface using virsh. When I go back to this session, you can see that there was a speed drop to 128 kbps, but the download wasn’t interrupted even though we disconnected the interface.
A few words about the right automation
Before we sum everything up, let’s talk about real life a little. There are some things that you always need to keep in mind:
- It’s unnecessary to set teaming up manually every time. You can use Kickstart for it, for example.
nmcli,tcand others are highly useful for fast configuring and debugging, but you will need such tools as Chef/Puppet/Ansible for automation in real environment.
A final word
Before we started writing this article we planned it as a short one about teaming in Linux only. Once we started we realized that there are many things that need to be discussed as well.
We gave switches a try and found out about several features, such as fdb.
We discovered tap interfaces and discussed their role in network virtualization in Linux.
We examined Linux Traffic Control, which means that now we know way more about Linux networking stack. Now, in theory, we can build sophisticated traffic processing sequences using tc.
We also got the gist of teaming and saw for ourselves how effective it is. Maybe someday it’ll come in handy. Even if it won’t, it always pays to know how some technology works.
We were playing around with libvirt and now we know how much it helps at work. A couple of lines of XML configuration file hide complex and flexible settings for several built-in Linux instruments which can be used on different Layers. All those instruments make virtualization possible, which is needed for work with all present cloud platforms.
We hope that networks now make more sense for you, virtualization doesn’t seem as some sort of black art and our tips and tricks along with the examples of usage of different instruments will prove useful to you when you try to solve problems connected with the infrastructure.
Further reading
We read hundreds of articles, docs and parts of the books while preparing for writing. Thus, we’ve covered lots of topics but haven’t dug deep into any of them. Below you can find some links for further reading with more detailed information:
man tc,man teamd.config,man bridge,man brctl- start with the documentation available on your computer.- teamd infrastructure specification – teamd creators use lay terms to describe teaming insides in Linux
- Configure Network Teaming — RedHat teaming docs
- Linux Bridge and Virtual Networking — explanation about how to create Linux bridge and add different interfaces to it without libvirt
- Tap Interfaces and Linux Bridge — the same author explains tap interfaces in simple words and pictures
- Tun/Tap interface tutorial — an article from 2010, which explains creating new interfaces in C
- QEMU Networking — different types of networks in QEMU explained
- VLAN filter support on bridge — an announcement of VLAN filter support on Linux Bridge
- Proper isolation of Linux bridge — an illustrated and easy-to-understand information about how to put VLAN into practice in Linux Bridge
- Linux Advanced Routing & Traffic ControlHOWTO — a huge mini-book about Traffic Control with good explanations and pictures (ASCII ones, though)
Article Series "Learning networks: from basics to advanced concepts"
- How networks work: what is a switch, router, DNS, DHCP, NAT, VPN and a dozen of other useful things
- How networks work, part two: teaming for fault tolerance, bandwidth management with Traffic Control, tap interfaces and Linux Bridge