Transaction Isolation Levels With PostgreSQL as an example
In this article, I'll explain what transaction isolation levels exist and what you should be aware of as a developer. We will consider only PostgreSQL (version 13) as an example database, so some information may be wrong if you would like to use another database.
For examples in this article, we will use pgcli utility. This is a nice analog for standard Postgres command-line interface that provides syntax highlighting and substitution. It can be easily installed e.g. via the brew package manager.
DevOps consulting: DevOps is a cultural and technological journey. We'll be thrilled to be your guides on any part of this journey. About consulting
There is a well-known database abbreviation ACID. It stands for Atomicity, Consistency, Isolation, and Durability.
.png)
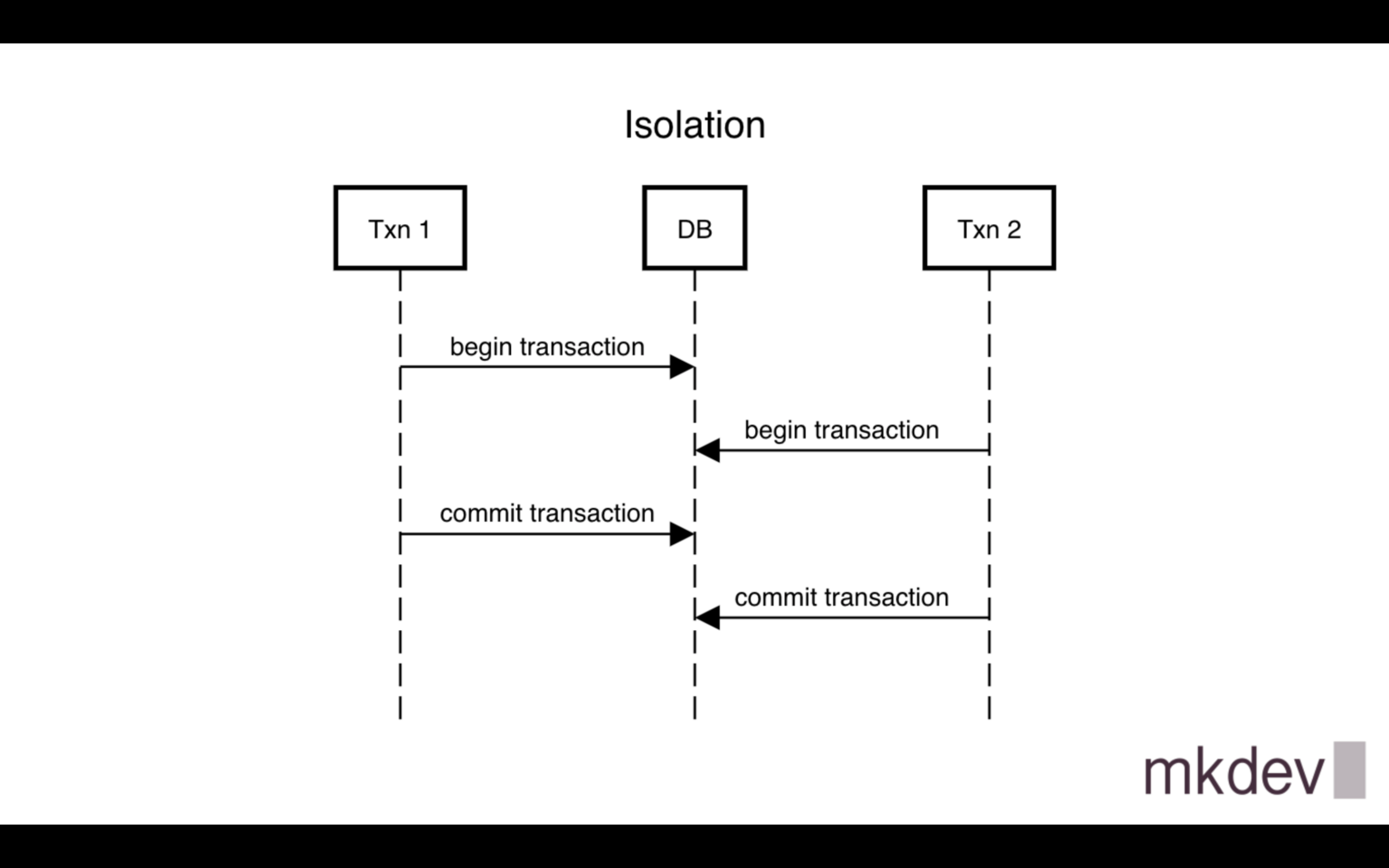
The term isolation relates to how concurrent transactions affect each other.
So if you develop backend software that operates data in a complex way inside database transactions you must be aware of how transactions affect each other to prevent your code from business-logic mistakes.
In classic SQL theory isolation levels is defined in terms of what must not happen or phenomena
- dirty read
- lost update
- non-repeatable read
- phantoms
- serialization anomaly
Let's define each of them separately.
Dirty Read
Dirty read means read uncommitted changes of other transactions. In PostgreSQL, it doesn't happen on any isolation level.
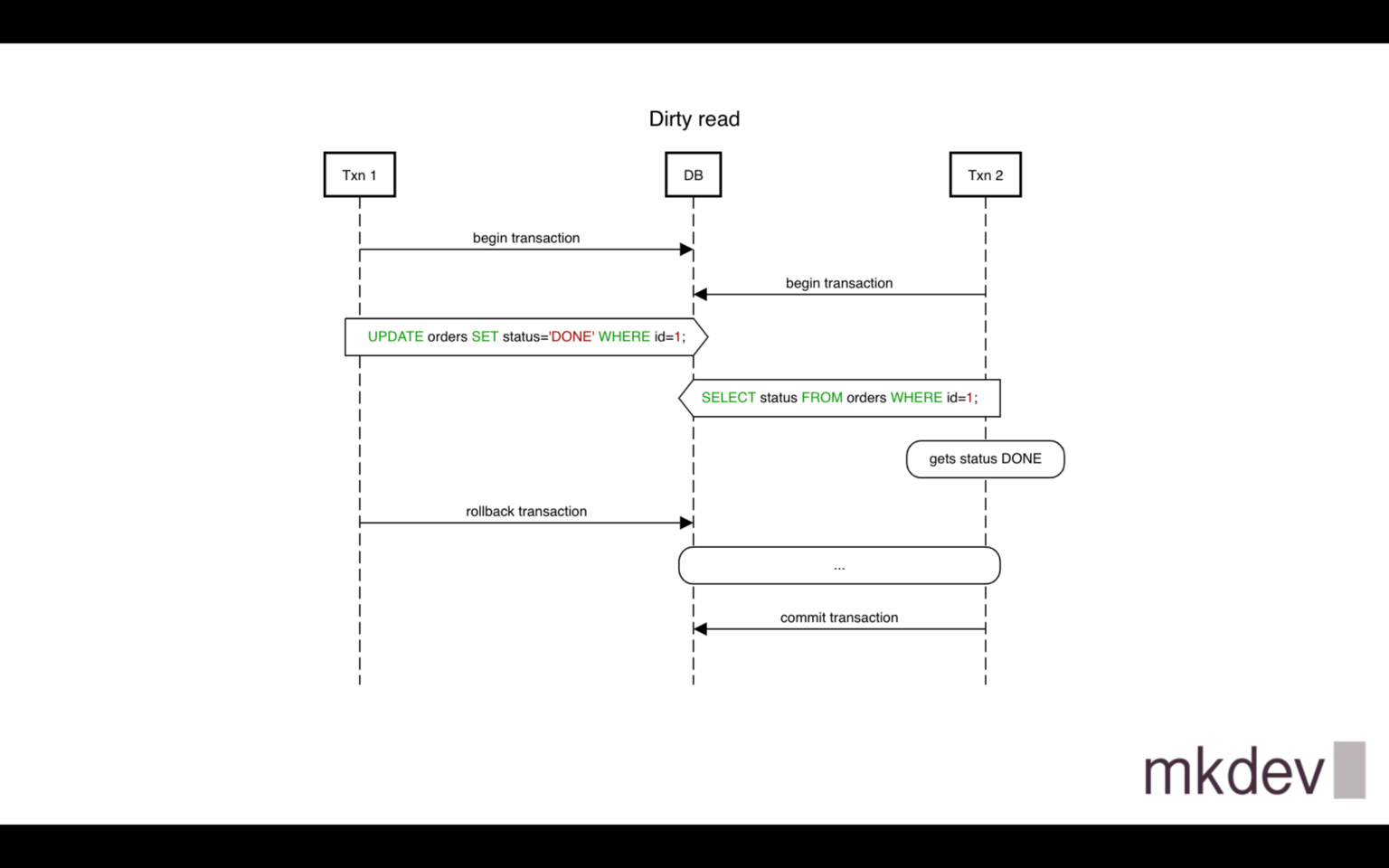
For example, the first transaction updates some record, after that the second transaction reads the same record and gets updated value even if the first transaction rollbacks later.
Lost Update
A lost update is when the first transaction reads data into its local memory, and then the second transaction changes this data and commits its change. After this, the first transaction updates the same data based on what it read into memory before the second transaction was executed. In this case, the update performed by the second transaction can be considered a lost update.
For live examples, we will use PostgreSQL running via docker-compose, consisting of one table named 'orders' that is populated with several seed records.
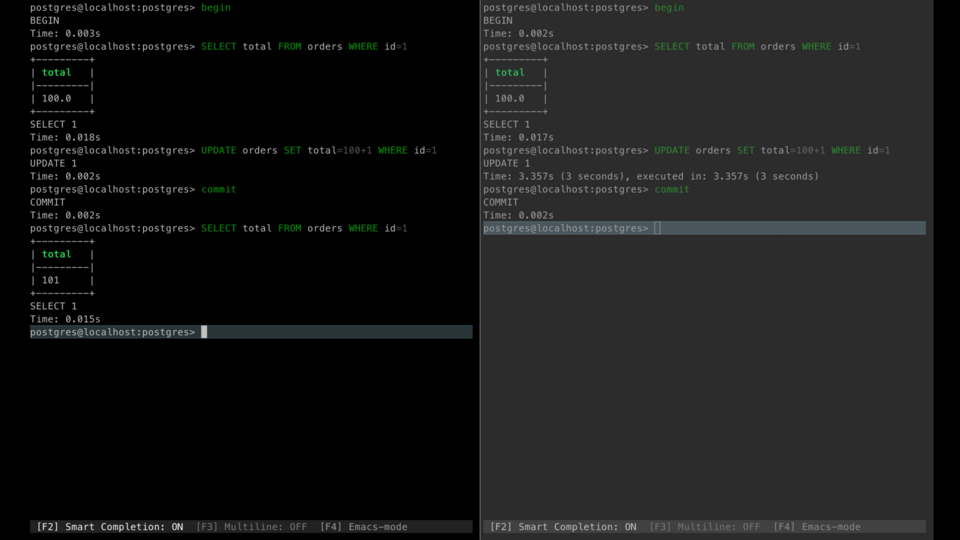
For example, the first transaction read order with id equals 1 and the second does the same. After that, each of them updates the total field value, and after committing both transactions only the last one will have a real effect.
Non-Repeatable Read
Non-repeatable read means that one of the rows you've queried at different stages of transaction may be updated by other transactions.
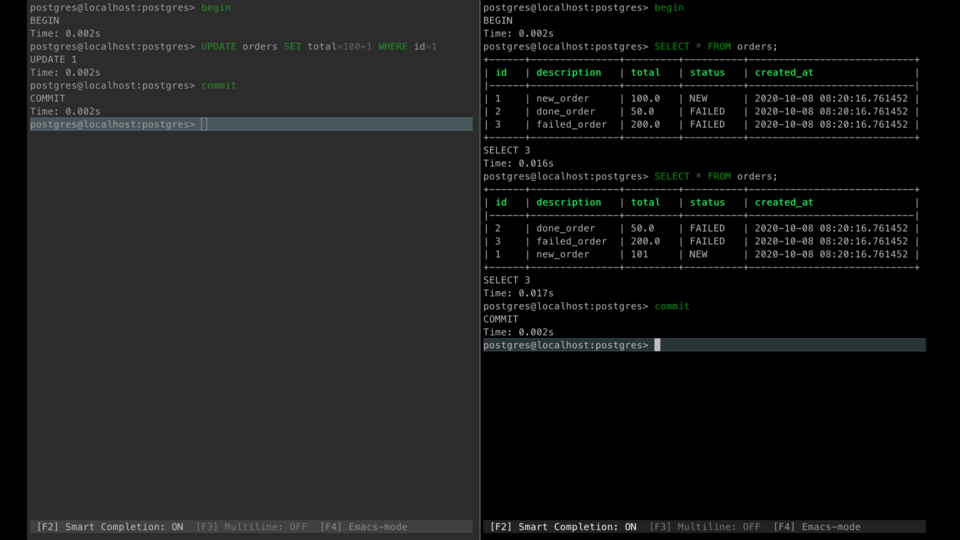
For example, one transaction reads orders. After that, another transaction modifies the total field for one of them with id equals 1 and commits. If the first transaction reads orders one more time it sees the updated record.
Phantom
Phantoms mean that some new rows are added or removed by another transaction to the set of records being read.
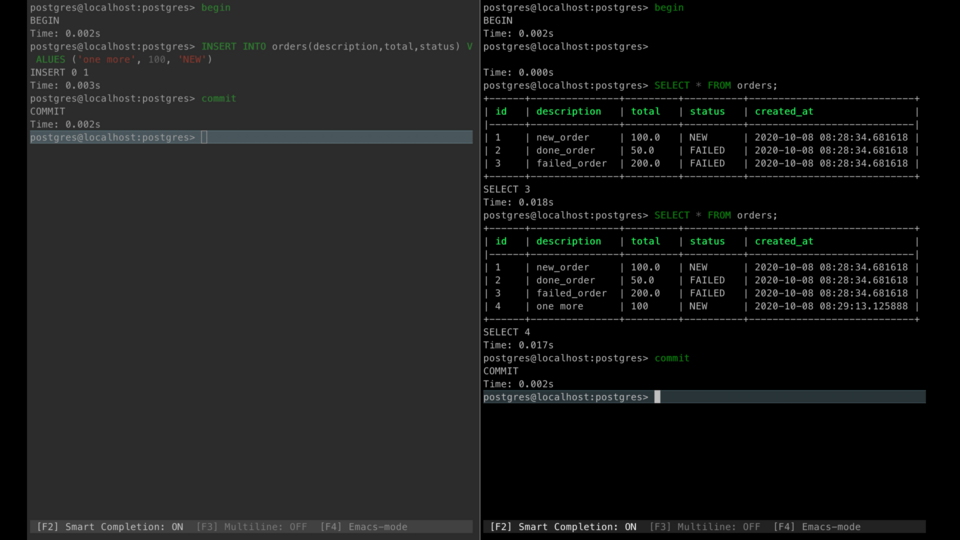
For example, one transaction reads orders. After that, another transaction creates one of them and commits. If the first transaction reads orders one more time it sees the new order record that can't be seen at first read. This record is called a phantom.
Serialization Anomaly
Serialization anomaly means that the result of successfully committing a group of transactions is inconsistent with all possible orderings of running those transactions one at a time.
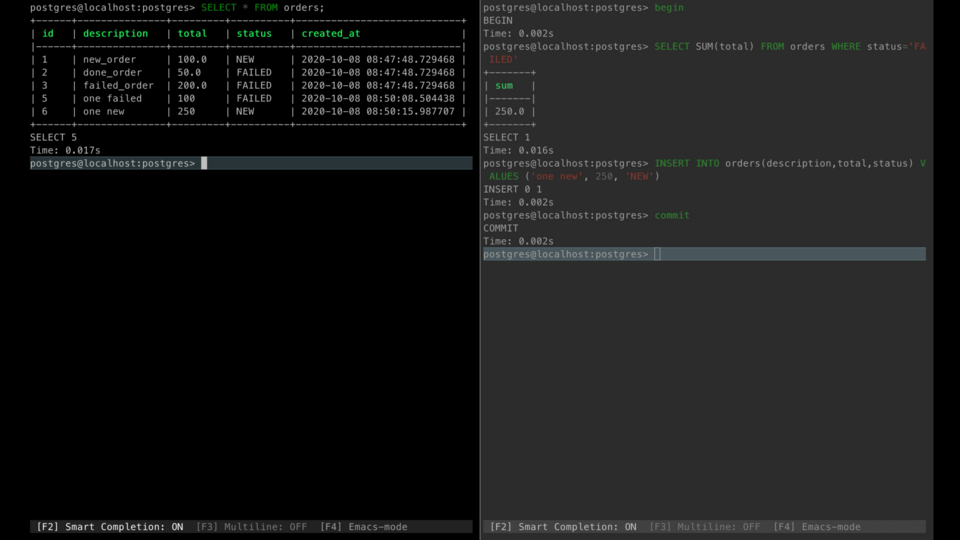
For example, one transaction reads the sum of the total field for the orders with status 'NEW' and the other does the same but for status 'FAILED'. After that, each transaction creates a new record with the opposite status, but with the total field equals the sum read.
After committing both of them there is no possible sequential order of these transactions that leads to the committed result because transactions are cyclic dependent on each other result.
In classic theory, there are 4 levels of transaction isolation and exact behavior for some of them depends on the database.
In the case of PostgreSQL version 13 they are defined the following way:
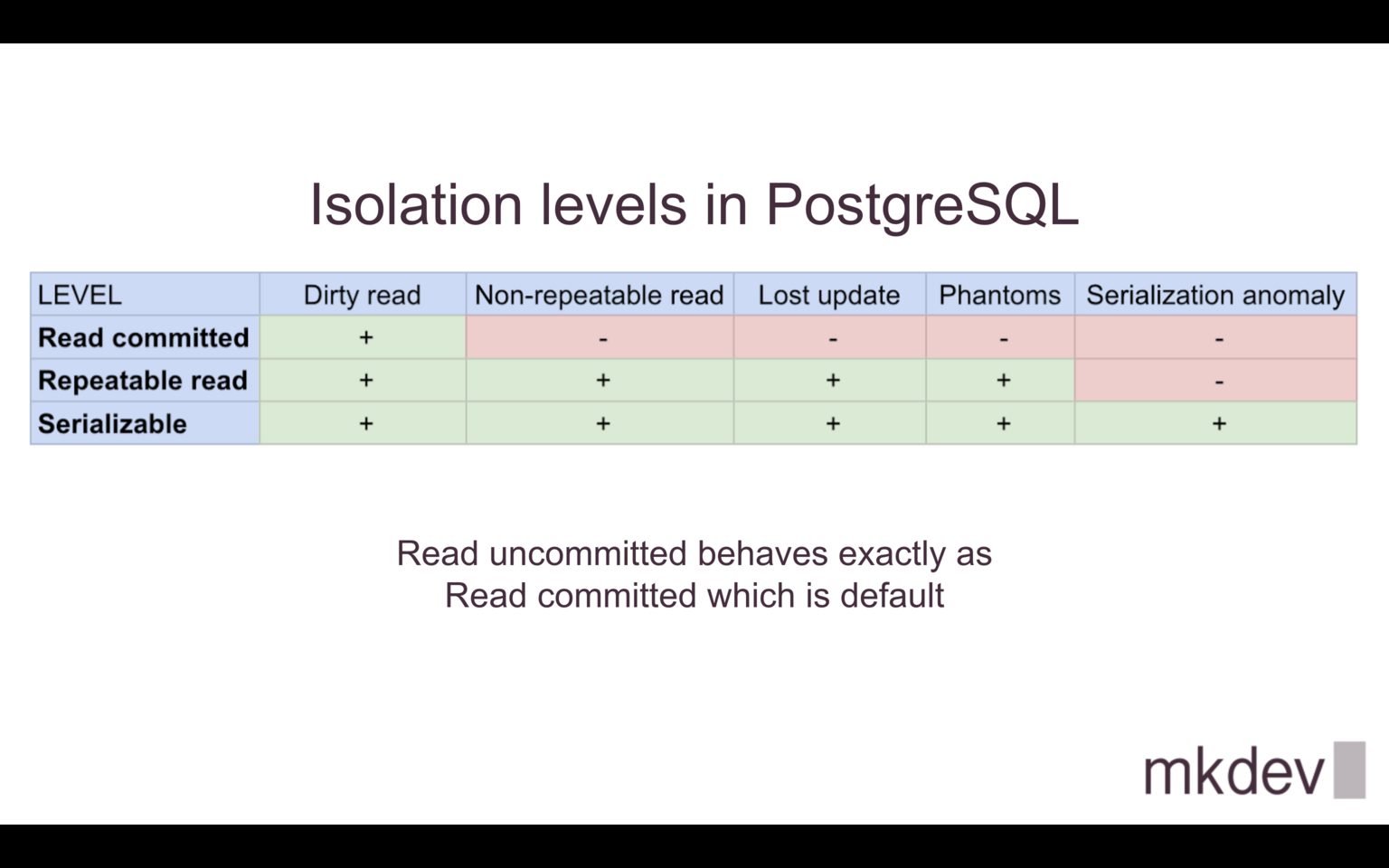
One can see plus sign if the isolation level is free of phenomena.
Repeatable Read
Repeatable read in PostgreSQL extends default Read committed level with guarantees of
- no non-repeatable read
- no lost updates
- no phantoms
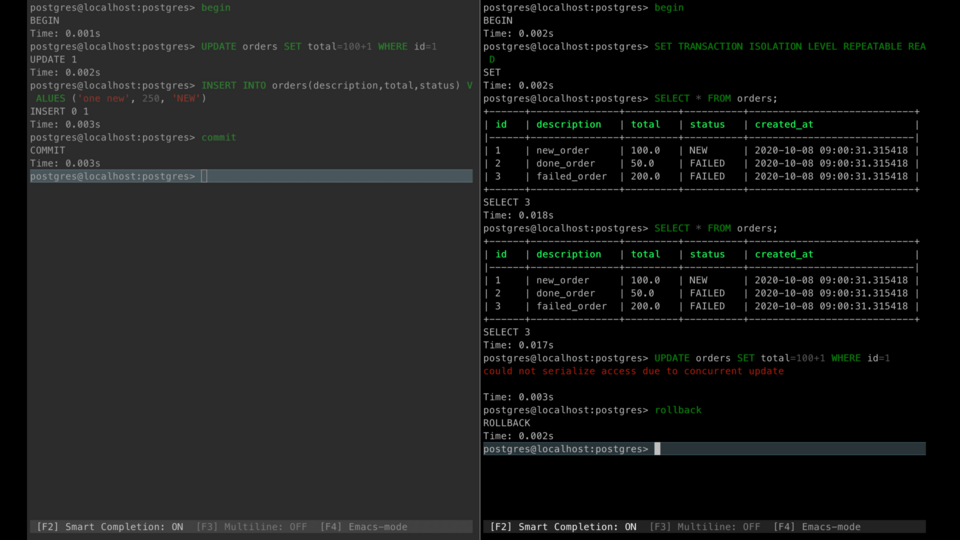
Let's repeat what we've done in several of our previous examples. The first transaction reads orders. The second transaction updates one of them creates one more order and commits. Now if the first transaction rereads orders it doesn't see any updates at all.
And if it tries to update already updated by another transaction record it gets an error that prevents lost updates.
Serializable in PostgreSQL extends Repeatable Read level with guarantees of
No Serialization Anomaly
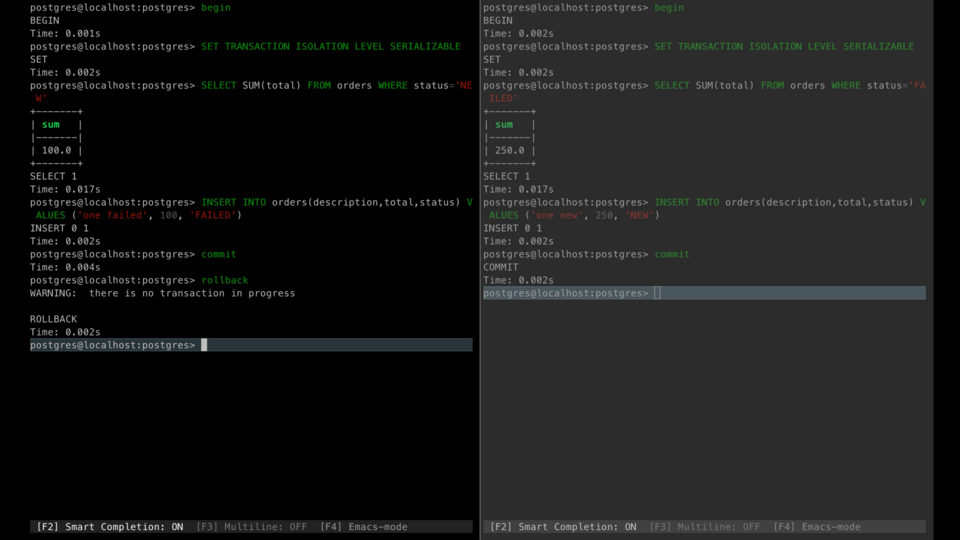.png)
Let's do the same stuff we did in the serialization anomaly example. After committing the first transaction, the second one gets an error when it tries to commit. This error prevents serialization anomaly.

One should also be aware of special errors for repeatable read and serializable isolation levels that the database return in case of impossibility to commit transaction with the chosen isolation level. In this case, it's up to your code to retry the transaction later.
Now you are aware of different isolation levels in PostgreSQL and can carefully use one of them when it's necessary or may decide to use explicit locks instead.
You should also keep in mind that the higher the isolation level the slower concurrency performance will be, so it's always a trade-off.
It's not an end-to-end guide about all isolation behavior so for specific details please consult documentation.
Here's the same article in video form, so you can listen to it on the go: