Processing Background Jobs on AWS: Lambda vs ECS vs ECS Fargate
By definition, background jobs are asynchronous and invisible to your users. As such, background workers - the software that processes the jobs - have completely different requirements in terms of availability and scalability. However, we often treat these workers on the same level as our traffic-serving workloads - we deploy them as constantly running container that consumes resources, regardless of whether there are any jobs at all.
Background jobs are a perfect fit for serverless infrastructure. There are multiple interpretations of what 'serverless' means, but in it's purest form, particularly concerning cloud costs, serverless implies that you are not paying anything if your software has nothing to do.
You could also setup serverless infrastructure for the apps that serve traffic, but you need to remember that users typically expect response times of under 1 seconds, ideally within 300ms. Setting up your synchronous workloads to run in a serverless mode usually requires warming up your functions, or specifying the minimum available "something" (this could be AWS Lambda Provisioned Concurrency, or GCP Cloud Run Minimum instanes). Whichever way you call it, such a setup remains serverless in theory, but in practice, you end up paying for always-on compute resources. This is not much different from having a server and, usually, much more expensive than having one.
One month since switching from Lambda to EC2. Cost savings are hundreds of thousands of dollars on annual basis.
— Mohamed Said (@themsaid) October 24, 2023
We haven't used reserved instances yet, and I'm convinced that by moving a few more endpoints from PHP to Go, we could reduce the number of instances to half. https://pic.twitter.com/qev5iOdEDw
Naturally, another core part of what "serverless" is about not having to manage or even think about servers. In this regard, provisioned Lambda or always-on Cloud Run instance are, undeniably, serverless.
What it takes to run a background jobs worker
Let's take mkdev case (the website you're currently looking at) and what it used to cost us to run our background jobs. On average, in 2023, we process 2,000 background jobs daily, or roughly 1.5 jobs per minute, with an average job duration of about 300ms. It's a modest scale. We are talking about, essentially, a content website. The traditional, most common way to process background jobs in Ruby on Rails is to use a software called Sidekiq. Sidekiq requires Redis to operate: your Rails application enqueues the jobs into Redis, and then Sidekiq reads from Redis to execute those jobs.

Sidekiq, the background worker, needs to run somewhere, meaning - another container(s), that consumes compute resources, that cost money. If we take the cost of ECS Fargate Spot, which is one of the cheapest way you can run a container on AWS, the minimum price for an always-on worker will be around $12/month, for 1 vCPU and 2GB RAM.
The storage for the jobs costs money as well. On AWS, you have 3 main options to run Redis on AWS:
ElastiCache, minimum price $13/month;
MemoryDB, minimum price $39/month;
Run it yourself, on EC2 or Fargate (on ECS or EKS or any other way), minimum price approximately 6-10$/month.
I must note here that the new ElastiCache Serverless could be a fantastic option.. except that it costs a minimum of $90/month, due to a minimum charge for 1Gb of data.
No matter which option you choose and how many background jobs you have, just to run the basic infrastructure for the background job processing on AWS will cost you a minimum of $20/month. If you are willing to use AWS like a VPS provider (something we recommend not to do), and just spin up a t4g.nano instance, you will still end up paying around $10/month. In our case, when using ECS Fargate Spot for both for Sidekiq and for Redis, our standard cost for background job processing was $20/month.

We were not comfortable running Redis inside Spot Fargate containers, as it meant that we could lose the container any second, together with all the currently scheduled jobs. Neither we wanted to start attaching EBS volumes and handling RDB snapshots.
For a certain period, we switched to Que, an alternative to Sidekiq that utilizes PostgreSQL as a persistence layer. The idea of using the good old SQL database as a backend for background jobs isn't novel. One of the earliest similar solutions in the Ruby on Rails ecosystem was DelayedJob, with more modern alternatives including Que and GoodJob.

Switching to the SQL-based persistence layer eliminates one component from the equation. There is not longer a need to run Redis, as you just use the same RDS cluster as your main application (up to a certain scale). This solves two problems at once: we don't pay anymore for Redis, and we are not afraid of losing the jobs due to container interruptions. The worker is still there, though. Que is an always running background process, that consumes compute resources regardless if there is anything to do or not.

AWS audit: Huge list of AWS services can be intimidating. We'll help you figure it out and choose the right solution for your business. About AWS audits
How much does the background job cost?
Previously, I mentioned that we have around 1.5 background jobs per minute, or 1 job every 40 seconds. On average, job takes 300ms to run. With a pull-based always-on worker, we are paying for 86,400 seconds per day, and we are only doing some work for 648 seconds per day, on average. This means that we are paying for 85,752 seconds of compute resources without doing any actual work.

As we are talking about per-second consumption, it's important to understand how much one second costs. This cost differs among different AWS services. In this case, we are comparing the pricing of ECS Fargate Spot and AWS Lambda.
Our Lambda function has 512Mb of memory, which AWS maps internally to an undisclosed amount of CPU power. Lambda is priced, for the first 6 Billion GB-seconds / month (x86 Lambda), at $0.0000166667 for every GB-second. There is a sample table provided by AWS that claims that 1ms of 512Mb Lambda function costs $0.0000000083 (in eu-central-1 region).
Let's compare it with AWS ECS Fargate Spot pricing. We have to pay both for vCPU and Memory. 512Mb of memory gets as maximum 0.25 vCPU, meaning that 1ms would cost:
(0.01425795+0.00156482)/(2*60*60*1000) = $0.000000002197607
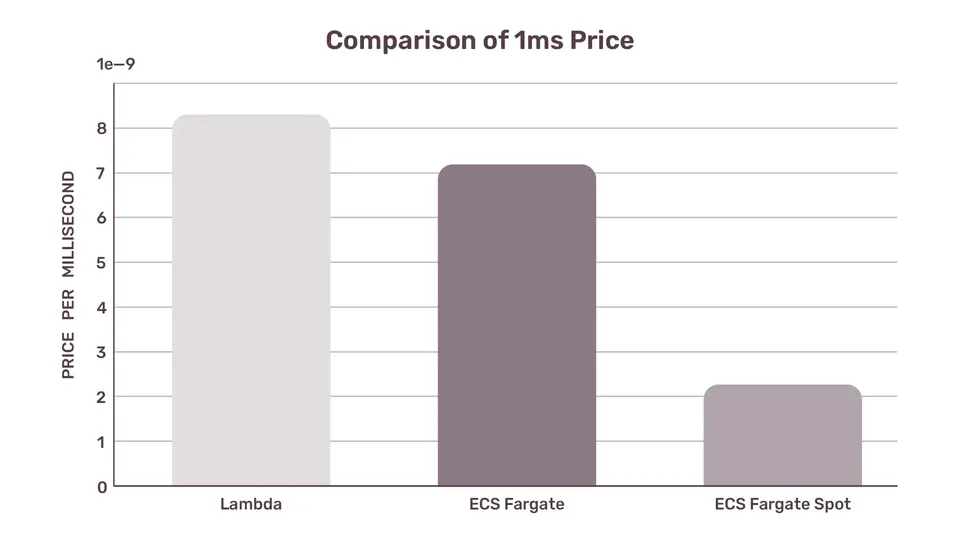
If we look at the per millisecond price, AWS Lambda is almost 4 times more expensive than ECS Fargate Spot. Fargate Spot is so cheap for a reason - those containers can be gone any second, in the middle of your background job. It would be more fair to compare it with the regular ECS Fargate per-millisecond price - $0.000000007176389. In this case, Lambda is only 15% more expensive than Fargate.
Cost of 1ms, 512Mb of memory, 0.25 vCPU
Lambda $0.0000000083
ECS Fargate $0.000000007176389
ECS Fargate Spot $0.000000002197607
Cost of 1 job (300ms)
Lambda $0.00000249
ECS Fargate $0.00000215291
ECS Fargate Spot $0.0000006592821
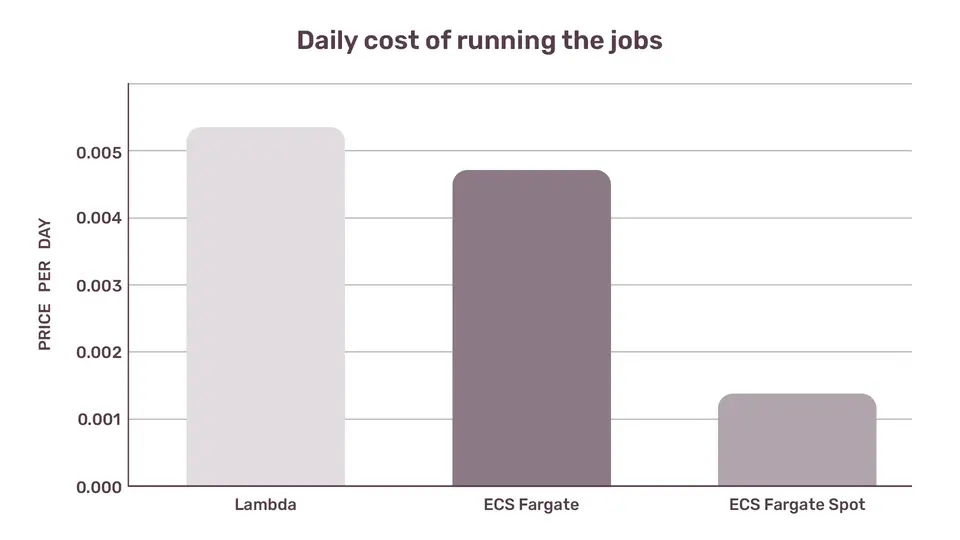
Let's be naive for a second and calculate the daily cost as 648,000ms * (Cost Per 1ms)
To remind where the number 648,000ms is coming from: we run 1 job every 40 seconds. There are 86,400 seconds in a day. That's 2,160 jobs a day, multiplied by an average duration of 300ms => 648,000ms.
Daily cost, calculated per-millisecond
Lambda $0.0053784
ECS Fargate $0.004650300072
ECS Fargate Spot $0.001424049336
Clearly, AWS Lambda is the most expensive way to run those jobs! Why would we ever choose it instead of ECS Fargate?
Reason #1: Lambda has 1ms billing granularity
AWS Lambda has 1ms billing granularity. On Lambda, single 300ms background job will cost us (Cost Per 1ms * 300).
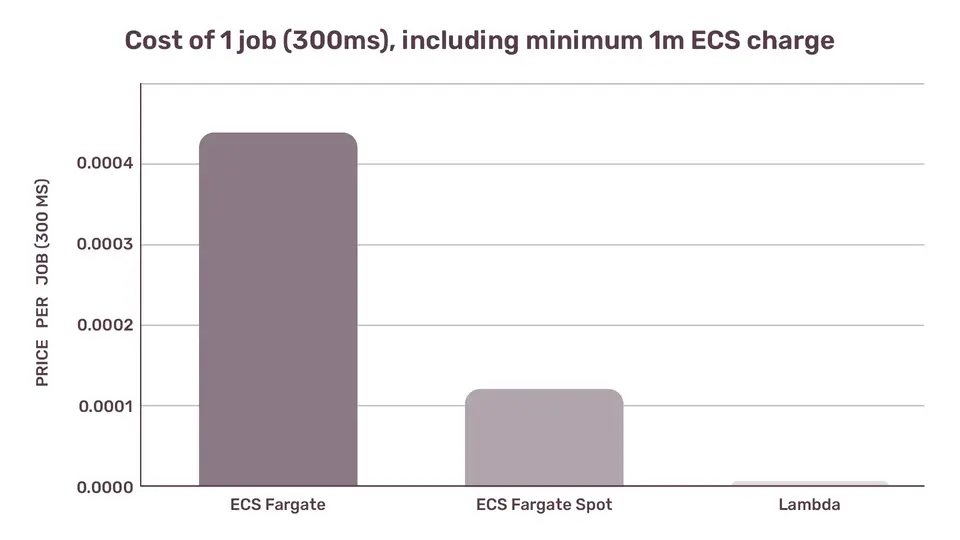
ECS Fargate has 1s granularity, with a 1-minute minimum charge. On ECS, the same job will cost us (Cost per 1ms * 60 000). Thus, even though if we look at the per-millisecond cost, Lambda is anywhere between 15% and 500% more expensive than ECS Fargate, in reality we never pay per-millisecond on ECS. Same 300ms job on Lambda and on ECS Fargate Spot will cost roughly the same, simply because on ECS we are going to pay for a full second - plus that extra 60,000ms minimum charge.

Thus more realistic per-job cost would look like this:
Cost of 1 job (300ms), including minimum 1m ECS charge
ECS Fargate $0.00043058334
ECS Fargate Spot $0.00013185642
Lambda $0.00000249
Cost of 1 job (300ms), excluding minimum 1m ECS charge
ECS Fargate $0.00000717638
Lambda $0.00000249
ECS Fargate Spot $0.0000021976
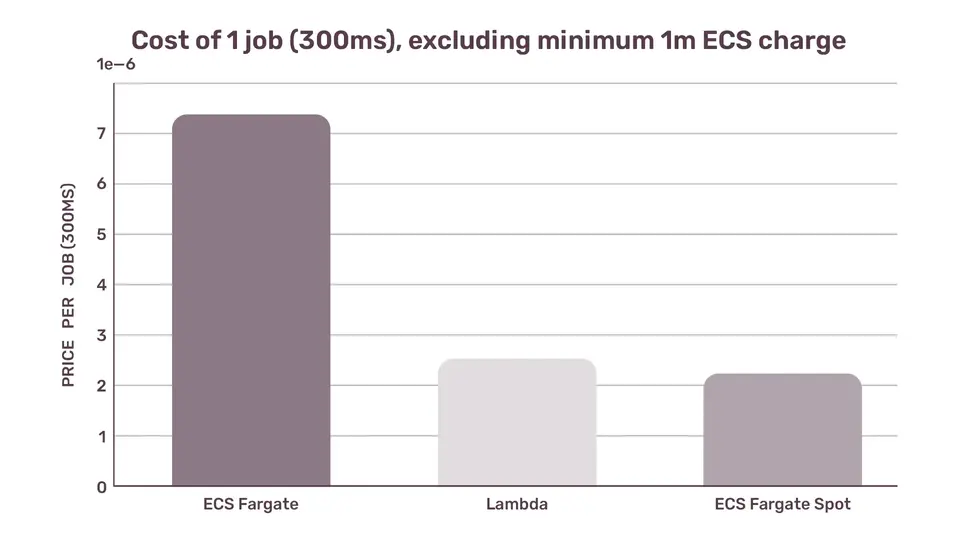
Per-millisecond granularity of Lambda aligns with the pay-per-use idea of Serverless way better than ECS's per-second granularity.
Reason #2: ECS Fargate runs 86,400s a day
ECS Fargate worker usually runs all the time, every single second of every hour of a given day. If we could trigger Fargate containers in a same manner as Lambda functions - push-based, only when there is something to do, then Fargate would be the most cost-effective way. But that's not how ECS Tasks are normally used. They run all the time, and they are waiting for jobs to appear in a queue.

Thus the real, none-naive per-day cost for running our background jobs looks like this:
Daily cost, ECS container runs 86,400s a day
ECS Fargate $0.6200400096
ECS Fargate Spot $0.1898732448
Lamda $0.0053784
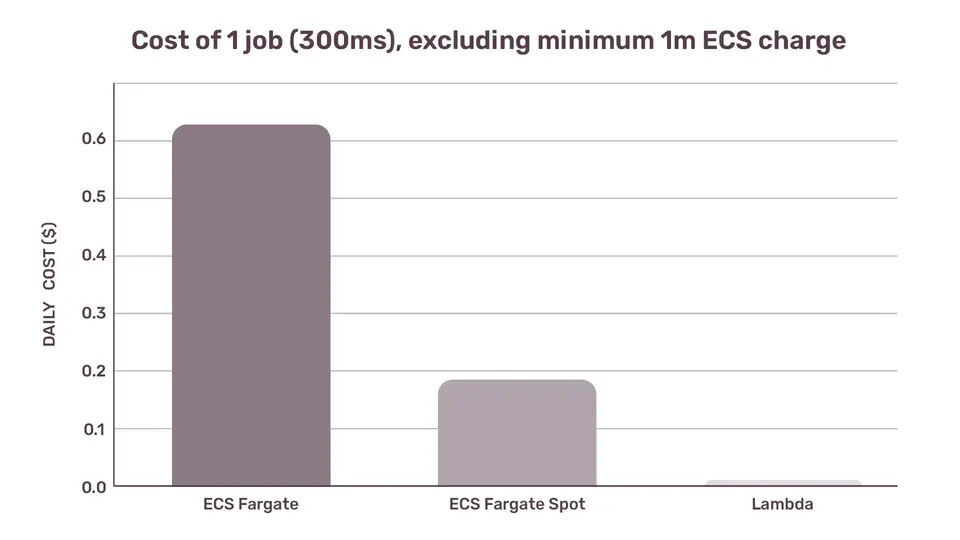
Lambda costs us less than 1% of the ECS Fargate costs, and 2.83% of the ECS Fargate Spot costs. In other words, it's almost 100 times cheaper to run those jobs on Lambda.
Serverless jobs storage
This brings us to the second aspect of Lambda-based background job processing: persistence for the jobs. We need a trigger for those Lambda functions. The simplest way to do that is to use AWS services that have native integration with Lambda, such as SQS, DynamoDB, Kinesis and so on. There are many possible triggers for a Lambda function, and those triggers serve as kind of a guarantee that the function will run only when there is a job to do.
SQS is the simplest way to achieve that, albeit one of the more expensive ones (it's not expensive, it's just more expensive than, for example, Kinesis). For Ruby on Rails applications, there is an official aws-sdk-rails gem, that, among other features, includes an SQS-based ActiveJob adapter. With minimal code adjustment, you can send your background jobs to an SQS queue instead of Redis or PostgreSQL. This SQS queue then serves as a trigger for a Lambda function, which processes those jobs.
SQS isn't free. It costs $0.40 per 1 million requests. With 40,000 to 50,000 jobs per day, SQS effectively becomes free, for the first million requests. However, at a really big scale, SQS can become costly, and alternatives like Kinesis should be evaluated - but that's a whole different topic.
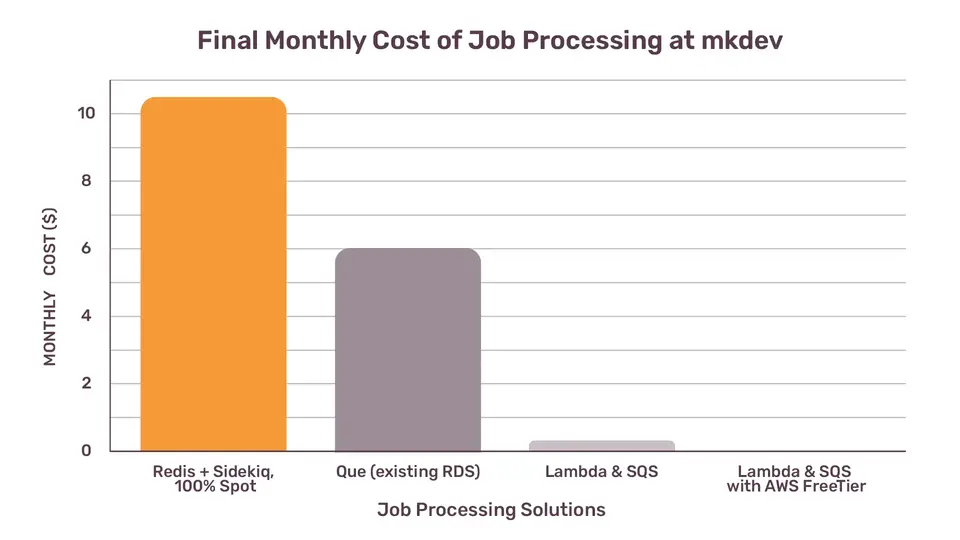
Final cost of background jobs at mkdev
Our initial setup, based on Redis and Sidekiq, costed around $11/month. The next iteration, when we got rid of Redis and moved to Que, was around $6/month. And the current iteration, with Lambda and SQS, is only $0.16/month.
To be completely transparent, the actual cost of our Lambda and SQS setup for mkdev is 0.0, because our usage (less than 1mln SQS requests, less than 400,000 GB-seconds Lambda executions) falls within AWS Free Tier, with some spare room on top. Worth mentioning, that there is no Free Tier for AWS ECS, you start paying as soon as your app is running. With Lambda, we can scale our existing usage 30 times without paying anything extra. Consider this: even if we were executing 45 jobs per minute, or one job every 1.3 seconds, our infrastructure cost would still be nil.
But even if the Free Tier didn't exist, the cost is significantly lower. With or without the free tier, processing background jobs for a small to medium-sized application will incur no cost, if you are ready to embrace the serverless approach.
Does it mean, that going serverless is always the best solution? It doesn't, of course. Let's dive a bit deeper and consider other scenarios.
What if we scale much further?
The reason I've presented the costs down to a millisecond level is because it lets us think about when exactly the fully serverless, pay-per-use setup stops being cost-effective. Let's look again at the table, that assumes we run our Lambdas only 648 seconds per day:
ECS Fargate $0.6200400096
ECS Fargate Spot $0.1898732448
Lamda $0.0053784
What if we run our Lambda's none-stop, 86,400 seconds per day?
Lamda $0.71712
ECS Fargate $0.6200400096
ECS Fargate Spot $0.1898732448
No surprises here, Lambda will be more expensive even than a regular ECS Fargate. But, the devil is, as always, in the details.
Compute Resources
Lambda's pricing is per-millisecond, per number of compute resources you configure, but it's up to you how long it takes to run a job. What if we double the amount of compute resources, and Lambda finishes the same job more than 2.5 times faster? In this case, the real cost will go further down.
Check out AWS Lambda Power Tuning as one of the ways to figure out how exactly the resource increase will influence your Lambda's duration.
What if you do the same on ECS? Your cost will double, period. You are still paying for all the seconds the day has.
Fractional scaling
I couldn't find a better term to describe it other that "fractional scaling", but bear with me for a second.
What if your jobs demand 120% of the milliseconds available in a day? With Lambda, you are going to pay 20% more. With ECS Fargate, the cost would depend on the resources you've allocated for your ECS Tasks, and their utilization at any given time. You may need to add more containers, or re-configure the resource allocation of the existing ones. In a simple scenario of having just 1 container that is ~90% utilized, you will have to add 1 more container, effectively doubling the cost (instead of the cost increasing only by 20%):
ECS Fargate $1.2400800192
Lamda $0.860544
ECS Fargate Spot $0.3797464896
Now, Lambda is significantly cheaper than ECS Fargate, but still more than twice more expensive than ECS Fargate Spot (don't forget the downsides of running on spot though). Naturally, in a real-world setup, with dozens, if not hundreds of ECS Tasks and/or Lambda function invocations, math looks way more intricate.
It get's even more nuanced, because you could also play around with different CPU/RAM combinations for your Fargate tasks - increase memory while keeping CPU the same, or vice versa (see possible combinations in AWS docs).
Reacting to spikes
Lastly, we need to consider the difference in how Lambda and ECS Fargate react to a spike in the load. In the default configuration, without any extra work from your side, and with the default AWS Quota Lambda will scale to 1,000 concurrent executions, 1,000 invisible Lambda MicroVMs processing your jobs. In the default ECS Service configuration, your ECS Service just gets overloaded. ECS necessitates careful planning around auto-scaling, including deciding which metrics and thresholds should trigger both upscaling and downscaling. That's the extra work you can avoid by using Lambda.
Serverless job processing
Is Lambda the best choice for running background jobs? As is often the case, it depends. If your jobs are resource-intensive or require GPUs, then Lambda is useless. You might have a lot of short-lived functions, like mkdev.
Background jobs align well with serverless concepts, such as pay-per-use, seamless scaling in and out, and easy maintenance. Labmda's per-millisecond billing granularity and trigger-based executions are a perfect match here. However, it's crucial to keep the real cost in mind and the alternatives you have. It might be, that spinning up an ECS Service will be more cost-effective for your particular workload. It's also not unusual, that plain EC2 instances will offer the best combination of price and performance. You have to do the math.
If you're not inclined to do the calculations, or lack the capacity to do them accurately, you can engage mkdev to conduct them on your behalf as part of our Cloud Costs Audit. Within 4-6 weeks, you'll receive a practical roadmap to enhance the scalability, security, and cost-efficiency of your cloud infrastructure. Schedule a call with us to discuss the details.