What is Kubernetes Downward API and why you might need it?

I want to share with you one lesser known feature of Kubernetes. It’s called the Kubernetes Downward API and it’s one of those things that you might not need on a daily basis, but every now and then you will certainly benefit from it.
When your application runs inside the pod, it’s not aware that it’s running inside Kubernetes - it knows nothing about the pod, the namespace, the deployment and all the other Kubernetes-specific entities.
And it’s good that it doesn't know that, because one of the core ideas behind using containers is to have portability. Your container image and your application should not care about the platform where they are running.
But sometimes you still want to get the information about the pod inside the container. One way to do it would be to use the Kubernetes API via some custom scripts, Kubernetes client tools or by modifying your application source code. While doable, this would make your container know too much about where it is running.
Kubernetes audit: it's a complex framework, and it's tricky to get it right. We are here to help you with that. About Kubernetes audits
Another way to do it is to use the Downward API.
The Downward API gives you two platform-agnostic ways to supply the information about the pod into the container inside the pod - either via the environment variables or via the files.
Let’s try both of them in my local Kubernetes cluster.
Here I have a simple job definition. This job simply echoes the name of the namespace where the pod is running. The namespace name is not available inside the container by default.
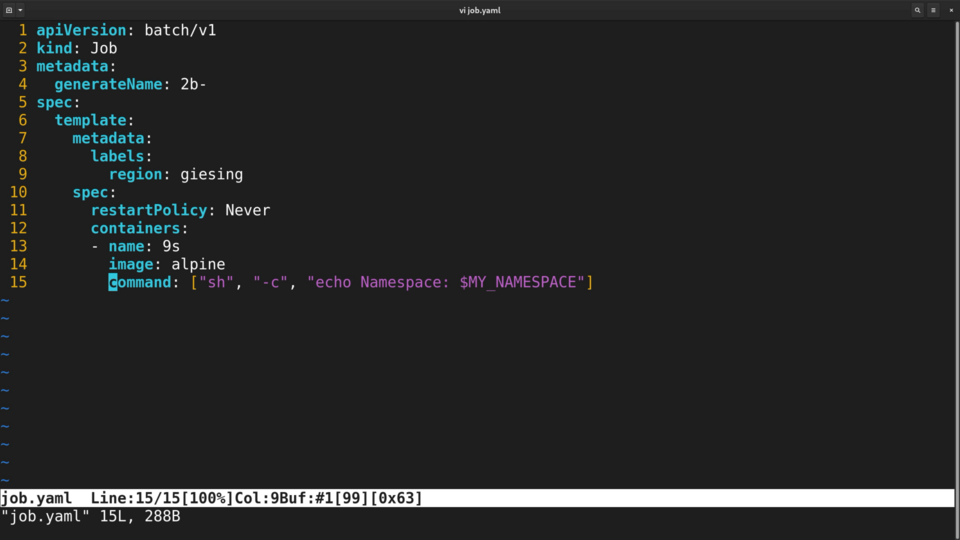.png)
To get it inside, I will define a new environment variable for this pod, named MY_NAMESPACE. The value of this environment variable will come directly from the pod.
To achieve this, I need write fieldRef, followed by fieldPath and then name of the field, in this case metadata.namespace. fieldRef is the way to access the Downward API.
When Kubernetes sees this, it will inject an environment variable into the container, with the value being the namespace where the pod is running. There are plenty of fields available to injecting like this - it includes the node name, the service account name and so on. You can find the full list in the documentation here.
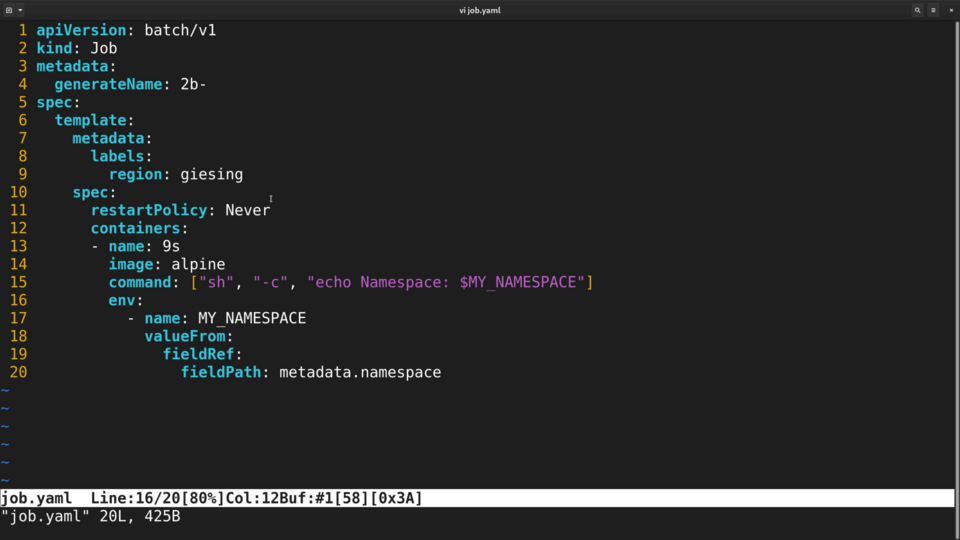.png)
Now let’s run this job and check the logs. Apparently, it runs in a default namespace!
The second way to use the Downward API is to mount the information about the pod into the container as a special volume. Let’s modify our pod specification to mount the pod labels into the container. I will name the volume “labels”, and reference the DownwardAPI fields via the same fieldRef key.
Let’s also modify the command container runs to cat the file where labels are mounted. Now let’s run the new job and check the log output.
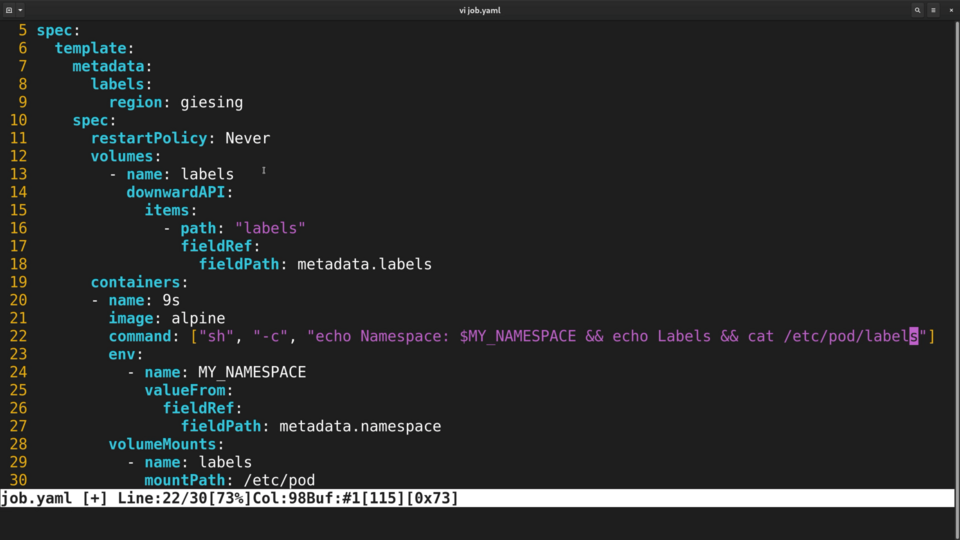.png)
We see that Kubernetes created a file with one label per line.
The Downward API allows you to get a lot of useful information about the pod into your application, without your application being aware of Kubernetes, because the Downward API works via environment variables and files, the two sources of information that any software can understand.
As I mentioned, this feature might not be required every day, but there are certain use cases for it. The most popular use case would be to increase observability - you can pass all of this metadata to the monitoring sidecar, and then it will enrich your metrics or logs with an extra information about the environment where application is running.
Tell me in the comments which Kubernetes feature you think more people should know about.
Here's the same article in video form, so you can listen to it on the go: