What is Tekton and how it compares to Jenkins, Gitlab CI and other CI/CD systems

Let’s talk about one of the hottest open source technologies in the CI/CD space: Tekton.
To discuss Tekton, or any other CI/CD system, we need to re-cap the concept of a Job Execution Engine. In short, we can look at the job execution engine as a system, that consists of 3 elements:
- A job server
- A job scheduler
- And a job executor
Any CI/CD system is a job execution engine. If we look at Jenkins, the Jenkins Server is a "job scheduler", "job server" is any server that has "jenkins agent" installed and "jenkins agents" are your "job executors".
Kubernetes itself can be considered a job execution system - it has a scheduler, that takes care of placing pods on the nodes, and.. we can consider pods a job executor, and the node, where the pod is running, a job server.
Naturally, there is a way to go for a simple job execution engine to become a fully-featured CI/CD system. Normally, a number of primitives are added on top of the aforementioned basic elements.
For example, every modern CI/CD system has a concept of a Pipeline - a series of jobs, often called Build Stages, that perform different tasks like building the software, testing and, finally, releasing it.
Another thing that CI/CD systems have are, quite often, a nice UI and many integrations with different tools. It’s hard to imagine a CI/CD system that doesn’t integrate nicely with a source code management system, like GitHub or BitBucket.
In general, CI/CD system has many many different layers on top of the simple job execution, and it makes it easy to build and deploy your software. A proper system like this abstracts the lower level details away from you and let’s you focus on building the continuous deployment pipelines in some form of a system-specific code, like gitlab-ci.yaml or Jenkinsfile.
Now let’s see how Tekton fits into this picture. Tekton is a “Kubernetes Native” CI/CD system - this means that, instead of having it’s own scheduler and primitives, it leverages Kubernetes as much as it can and it requires a Kubernetes cluster to be deployed - there is no Tekton without Kubernetes.
It is impossible to talk about Tekton, or understand what Tekton is, without knowing Kubernetes. From this moment, I will have to use Kubernetes-specific terminology. If the words like pods, custom resources, controllers and others are foreign to you, then you can already imagine one of the specifics of Tekton - it’s so Kubernetes-dependent, that without Kubernetes knowledge you can’t even make sense of it.
DevOps consulting: DevOps is a cultural and technological journey. We'll be thrilled to be your guides on any part of this journey. About consulting
The primitives that Tekton adds on top of the simple job execution are implemented as a Kubernetes CustomResourceDefinitions. The job is implemented as a Task custom resource, and to run the Task you need to create a TaskRun. To chain multiple Tasks together, you need to create a Pipeline - another custom resource. And to run the Pipeline, you create the PipelineRun. Both Tasks and Pipelines can be fed with different inputs, in form of params, ConfigMaps, Secrets, Volumes and so on. Those are the basics of Tekton.
The usage of CRDs allows Tekton tasks and pipelines to be easily re-usable. You can define organisation-global set of Tasks to perform common operations, and construct pipelines out of this tasks - and you can even have a set of common pipelines, applicable to every application of the same type.
Inside Tasks there is nothing but pods. Every task runs as a pod, from a container image, with some steps performed inside the container. You can provide the specification for this pods and do anything that you would normally do with Kubernetes pods.
So, how do you create new TaskRuns and PipelineRuns? One way to do this is to use the Tekton CLI or kubectl. But that, of course, is not ideal, as you need a human to do that.
Another way is to use one more object from Tekton - EventListener. EventListener is a special Deployment with a Service that listens for HTTP requests and processes them by using Triggers, which are, in turn, depend on two more objects - the TriggerBinding object, which maps the received payload to Tekton params, and a TriggerTemplate, which gets those params and generates a new PipelineRun.
Naturally, all of those objects are a lot of YAMLs to automate. Just like with tasks and pipelines, you can create a set of common trigger templates and trigger bindings.
Let’s draw the full picture of a simple pipeline - imagine, we simply want to lint some YAML files on a new Pull Request in a GitHub repository. Don’t worry too much about the details of each of the components - if you start looking inside those boxes, you will get crazy.
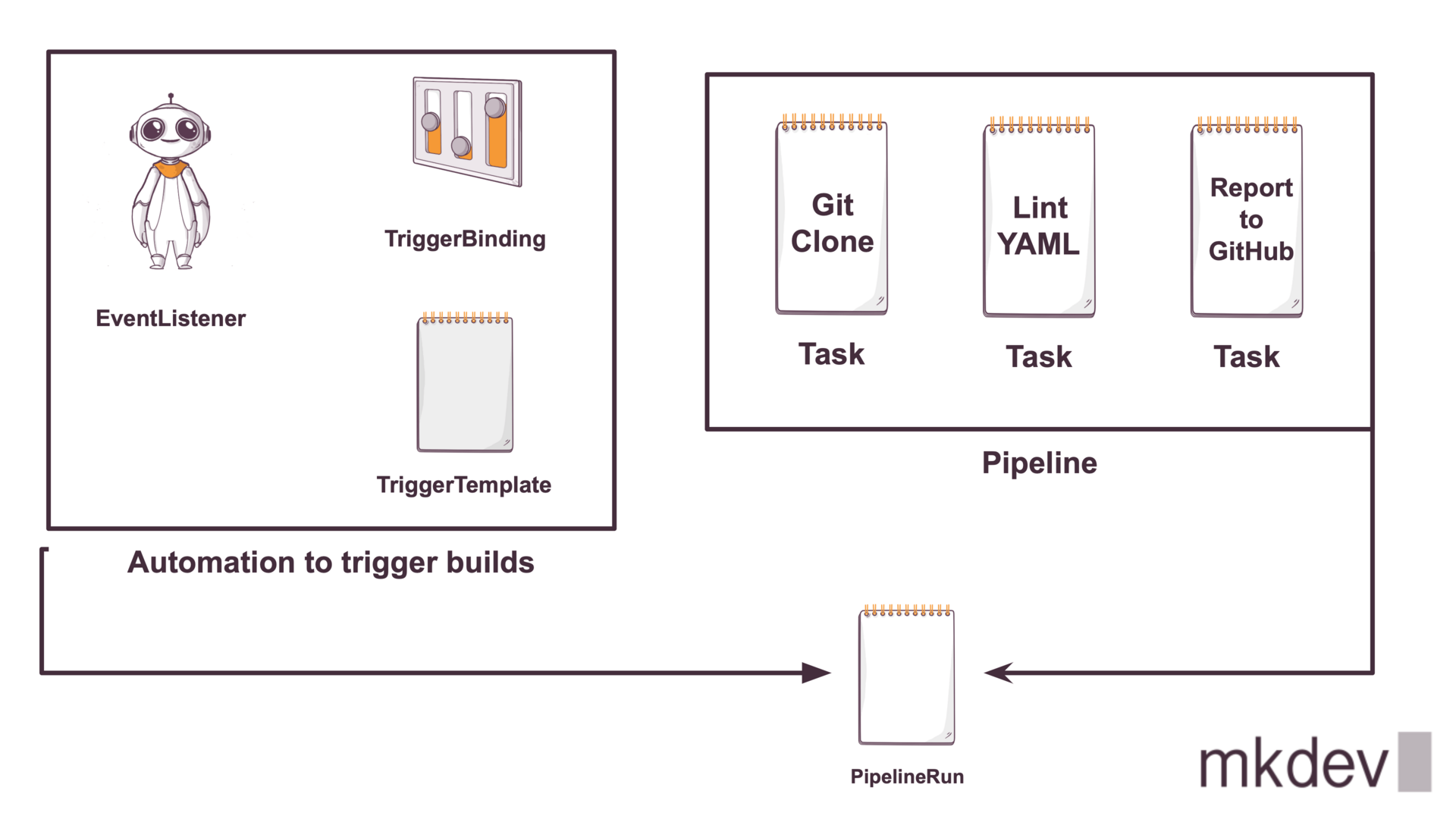.png)
First we need 3 Task definitions - to clone the repo, to lint the files in the repo, and to report the result of the build back to GitHub.
We also need a Secret with Git credentials, a persistence volume so that Lint YAML task can access the repository cloned in the Git Clone task, and a ServiceAccount so that Tekton can access the Secret internally. But let’s omit those details from the picture.
We need to chain these tasks in a Pipeline.
To trigger the Pipeline, we need an EventListener - for each EventListener, Tekton will create a new Service and Deployment - and you need to expose this Deployment with an Ingress or an OpenShift Route.
As mentioned before, Listener needs to map request to TriggerBinding and TriggerTemplate. Keep in mind, that you will probably need multiple TriggerBindings and TriggerTemplates, as well as something called an Interceptor - at least one per event type that you want to process.
Finally, the PipelineRun will be created and your build is running.
To build such a pipeline, we need to create objects of 6 different types, including multiple tasks. In addition, this would also require creating Secrets to connect to GitHub and PersisentVolumes to share the state between the Tasks inside the Pipeline. Once we go beyond the single pipeline, we end up with a huge amount of such objects.
We would need to properly plan how we want to organise and deploy Tasks and Pipelines, which images we use inside Tasks, how we maintain EventBindings and so on. We would have to combine the knowledge of Kubernetes with the knowledge of Tekton specific objects to build our CI/CD system.
And this is the most important thing to know about Tekton - it’s not a fully-featured, ready to use CI/CD system, like Gitlab CI or Drone CI or many other systems. Instead, Tekton is a - already very powerful - set of CI/CD primitives that you can use to build your own CI/CD system, or even general purpose task automation system.
It’s the same difference as between Kubernetes itself and a Platform as a Service solution - Kubernetes gives you all the building blocks to create your own platform as a service, but Kubernetes itself is nowhere close to being this kind of platform out of the box.
Having such a flexible set of building blocks that Tekton provides let’s you build truly flexible, powerful and tailored to your organisation CI/CD systems, that you can easily move between different Kubernetes clusters by simply re-applying the resource definitions. But you need to remember that it’s a lot of work and you might be better off by using an existing, ready to use solution.
That being said, I personally love Tekton, exactly for this approach of giving you the building blocks. It might not be useful for a smaller setups, but it can bring amazing benefits for mid to large organisations. If you want to learn about Tekton in details and how to use it, please tell in the comments below.
If your company wants to migrate to Tekton, or introduce it from scratch, mkdev consultancy team can help you with that!
Here's the same article in video form, so you can listen to it on the go: