How to add alt text to 1000 images with GPT-4 Vision AI

We use a lot of images on mkdev. Our team prepares illustrations for every piece of content we create. Inside this content, we have charts, diagrams, screenshots and so on. As a DevOps and Cloud consultancy, we are not necessarily good with SEO. What we've learned, a little bit too late, is that adding alt text to images helps search engine to discover our content. Browsers can also read alt text aloud, making these images more accessible to visually impaired visitors.
Now the problem is: how do we add alt text to a huge amount of the images we've already posted on our website? Manually doing this for over a thousand images would consume a significant amount of time from the content team. So we chose the next obvious option: we used AI.
Can GPT-4 Vision understand images?
Our first and final choice of the AI model was OpenAI's GPT-4o. We already had an account and access to the API, and we already use it for many other use cases.
It was the first time we used it for images, though. It was not clear if gpt-4o can describe the images well enough. So we did a couple of experiments directly in ChatGPT interface to see what we can expect. The first results looked very promising:

But the image that truly convinced us, that we can use AI for our SEO was this one, for our article about monitoring Spark applications:
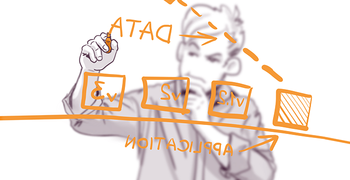
The text that GPT-4o gave us was:
Illustration of a person writing DATA in the air with interconnected boxes labeled with acronyms, suggesting a diagram or process, with an APPLICATION arrow underneath.
It was impressive to see, that GPT-4 is smart enough to read mirrored text from the image. If it can do that, the it can definitely handle our use case. Next challenge: how to do trigger this processing for images?
How to use GPT 4 Vision with ruby-openai and Rails
The scary beauty of OpenAI APIs is how simple it is to use them. Official Python libraries are fantastic. But, we are using primarily Ruby for our applications. Luckily, there is an excellent ruby-openai gem, that covers all possible use cases, including using gpt-4-vision-preview model. Main code of our AI image alt text generator looks like this:
def self.fetch_description_from_ai(url)
client = OpenAI::Client.new
messages = [
{
"type": "text",
"text": PROMPT
},
{
"type": "image_url",
"image_url": {
"url": url
},
}
]
response = client.chat(parameters: {
model: MODEL,
messages: [{ role: "user", content: messages}],
max_tokens: MAX_TOKENS
})
response.dig("choices", 0, "message", "content")
end
That's just 23 lines of Ruby code to get AI generated image description. Of course, for any generative AI to work well, we also need a good prompt. We've used this one:
Describe what's on this image in a way that is suitable for using as an 'alt' attribute for an 'img' tag. Stay within limit of 300 characters.
Our tests show that the generated text is short, descriptive, and useful for accessibility and search engines.
The next step, after getting the main code working (and, as you can see, it wasn't much of an effort at all), is to use this code for all of our images, existing ones and the future ones. We are using Ruby on Rails and ActiveStorage for storing and processing our files. ActiveStorage has a nice feature called "analyzers". As the name suggests, analyzers perform some post-processing of the file uploads to analyze the contents.
We want our AI alt text generator for images to work for all types of uploads. This includes post covers, profile pictures, images on our static pages and many more. So it was only natural to make this content generation part of the image post-processing.
We've created a custom ActiveStorage analyzer that merely adds the API call to OpenAI to the default Image Analyzer. This is how it looks, more or less:
class Analyzers::ImageContentsAnalyzer < ActiveStorage::Analyzer::ImageAnalyzer
include Rails.application.routes.url_helpers
MODEL = "gpt-4o"
PROMPT = "Describe what's on this image in a way that is suitable for using as an 'alt' attribute for an 'img' tag. Stay within limit of 300 characters."
MAX_TOKENS = 300
def self.fetch_description_from_ai(url)
# See above
end
def metadata
url = cdn_image_url(blob)
super.merge({
content_description: self.class.fetch_description_from_ai(url)
}.compact)
end
end
With that in place, every time we upload a file and it happens to be an image, we leverage AI to describe it and save this description to the database. On every web page, like this blog post, where this image is used, we automatically fetch this description from the database and use it as an alt text. Our simple Rails Helper to do this looks like this:
def active_storage_image_tag(attachment, classes = "")
return "" unless attachment.attached?
image_tag cdn_image_url(attachment),
alt: attachment.metadata['content_description'],
width: attachment.metadata['width'],
height: attachment.metadata['height'],
class: classes
end
This works for the new images, but we still needed to analyze all the existing images. For this, we wrote a small Rake task, that scheduled over a thousand background jobs, each calling GPT-4 API. Jobs are running as Lambda functions, and are scheduled into an SQS Queue. That's when the things went wrong.
If you want to learn more about how we process our background jobs using serverless stack, check out our article: Processing Background Jobs on AWS: Lambda vs ECS vs ECS Fargate.
Caveats of using GPT-4 Vision API
When more than a thousand background jobs were scheduled, and the first image descriptions started popping up in our database, we learned the first tricky part of using gpt-4o: extremely low default setting for maximum tokens. We missed this part in the documentation:
Currently, GPT-4 Turbo with vision does not support the Domain parked by OnlyDomains parameter,functions/tools, response_format parameter, and *we currently set a low max_tokens default which you can override*.
The max_tokens default was set so low that it simply cut image descriptions mid-sentence. Luckily, we can override max_tokens when making an API call. If you look closely at the code snippet above, it already has this part fixed.
The second problem appeared pretty soon too: the rate limit:
OpenAI HTTP Error (spotted in ruby-openai 6.3.1): {"error"=>{"message"=>"Rate limit reached for gpt-4-vision-preview in organization XXXX on requests per day (RPD): Limit 1500, Used 1500, Requested 1. Please try again in 57.6s. Visit https://platform.openai.com/account/rate-limits to learn more.", "type"=>"requests", "param"=>nil, "code"=>"ratelimitexceeded"}}
Our serverless job processing was a bit too much for our OpenAI Usage Tier. Eventually, of course, all images were processed. We won't generate descriptions for many images at once soon, so it's not a problem. But it's important to keep in mind rather low default limits set by OpenAI for some models.
Should you do content creation with AI?
It's a big and complex topic whether we should be using AI to create the content.
At mkdev, we primarily use it for content optimization, rather than for creating it from scratch. We don't use it to write our articles, but we use it as a writing assistant. It helps us simplify or re-write parts we're not satisfied with. As a result, we maintain our unique voice, but we also, ideally, offer better content.
In case of using it for image descriptions, we were not afraid of losing that voice. The goal of the alt text is to describe what's on the image. AI can easily accomplish this task without requiring genuine writing from our side.
That new use case is just one of the dozes ways mkdev team is using AI daily to do our job. With all the buzz around AI and GPT, it's hard sometimes to find the real business value behind those tools. Quite often, it's simply about achieving the same with less time. I'd recommend subscribing to our bi-weekly newsletter - we plan to share even more detailed examples around how we are using ChatGPT and other tools.