How to deploy Applications within Projects in Argo CD

We have an Argo CD up and running. We have repositories with the code we want to deploy, and we clusters we want to deploy to. The final step is to map which repositories should be deployed to which clusters - and for this we need to learn what Projects and Applications are.
Projects are the top level grouping of applications, and each application belongs to only one project. There is already a default project in here, but let’s create a new one. It’s up to you how to configure projects and applications - you can structure them in any way that works for your organization. In this course, I will create 1 Project per environment - I can, if I want, restrict which users and teams have access to which project. Let me create a “production” project.
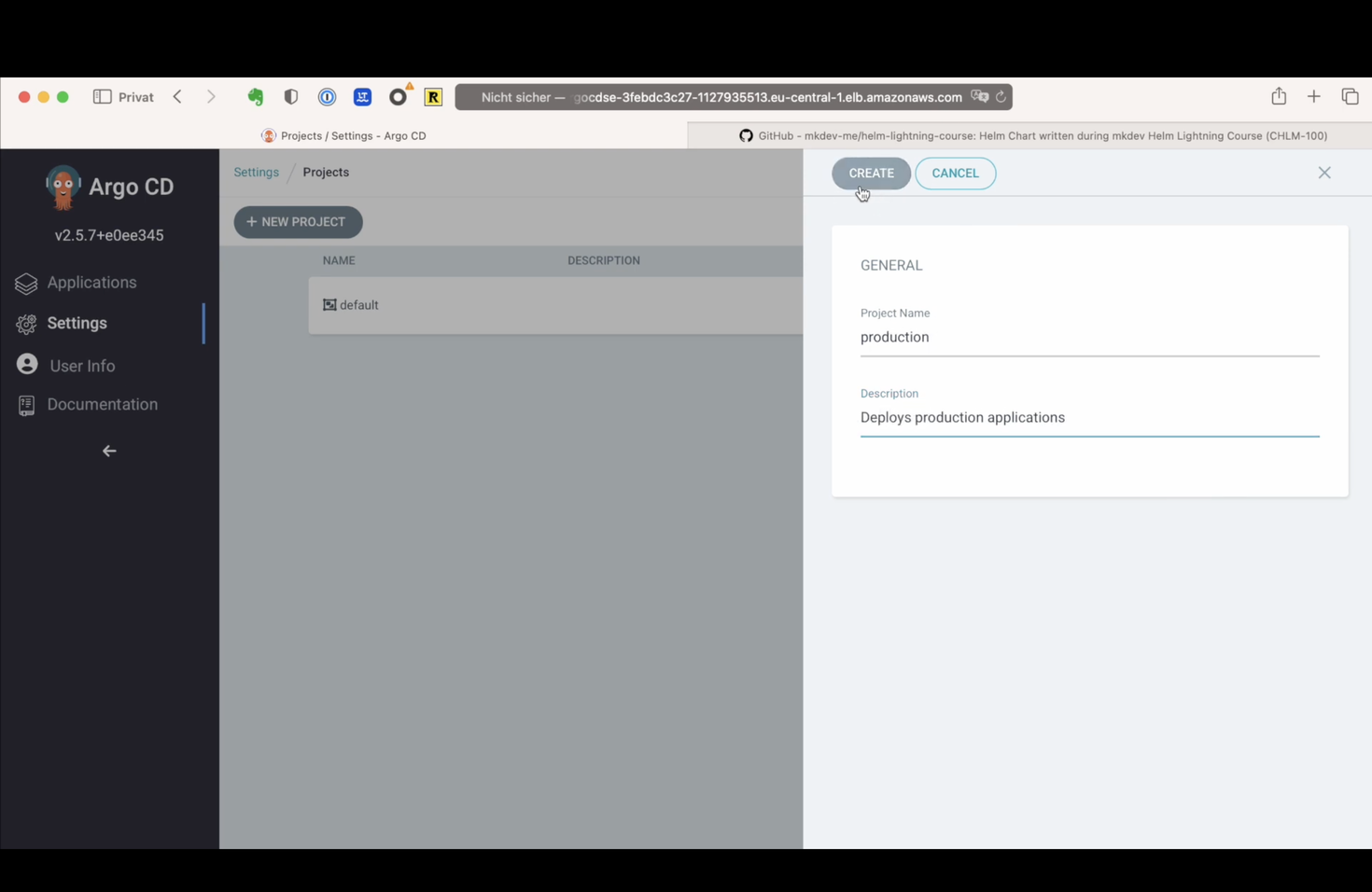
The next step is to configure which repositories are allowed to be deployed within this project. I can specify a wildcard, allowing any repositories, or I can specify concrete repos - let me pick the PGAdmin Helm Chart that we’ve added in the previous lesson.
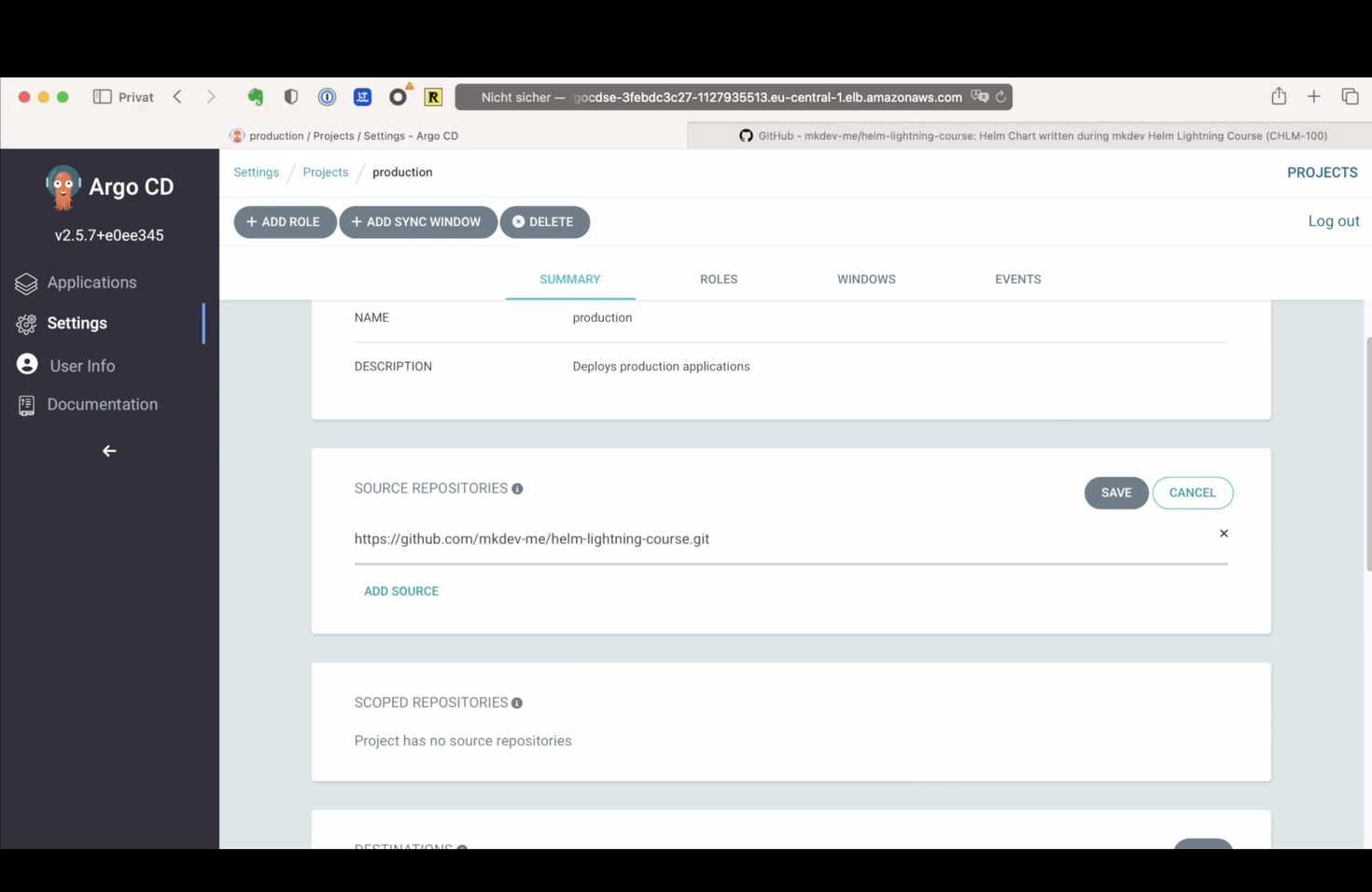
Next I can specify which clusters are allowed for this project. I will specify the production cluster, and allow all the namespaces within this cluster. I am not going to create any new roles for this project, neither I will dive deep into sync windows for now. Instead, let’s add an application.
I will name this application simply “pgadmin”, and I want it to be part of a production project. If I want to deploy the same code to multiple environments or clusters, I need to create multiple applications, either within the same project or in different projects - depending on how I decided to structure my Argo CD installation.
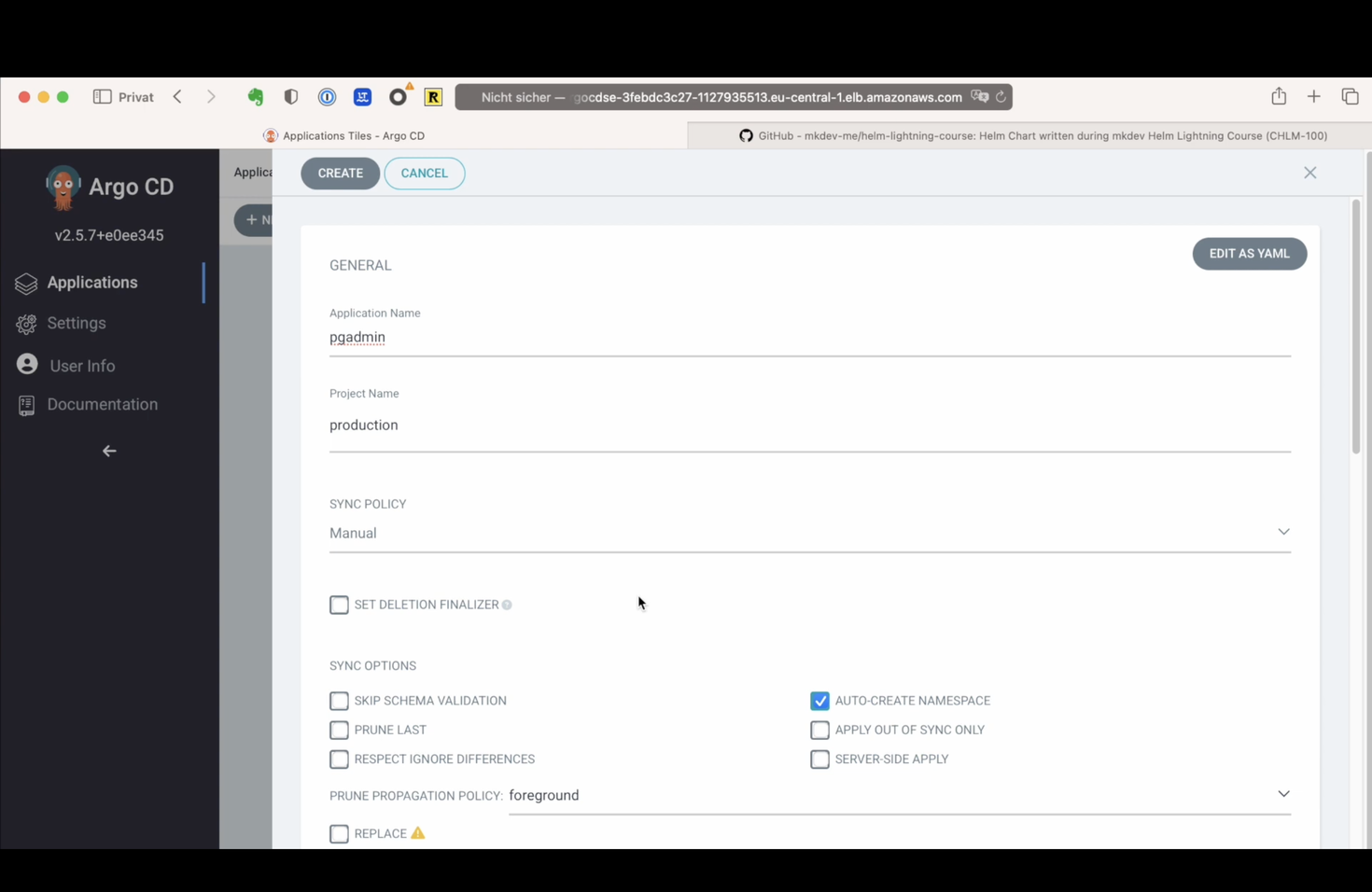
I will select a “Manual” Sync Policy - it means that I need to click a button to actually deploy anything. I also want to create a namespace automatically. There are a couple of other options in here, but let’s proceed to specifying the code for this repository. I am choosing the pg admin helm chart, and I need to specify that the code is located at the root of the repo. I need to tell Argo CD that this is a Helm application, and I can specify which values file to use - it will pick up the default values file automatically, and on top of this I want to use the production values file. Let me click on create.
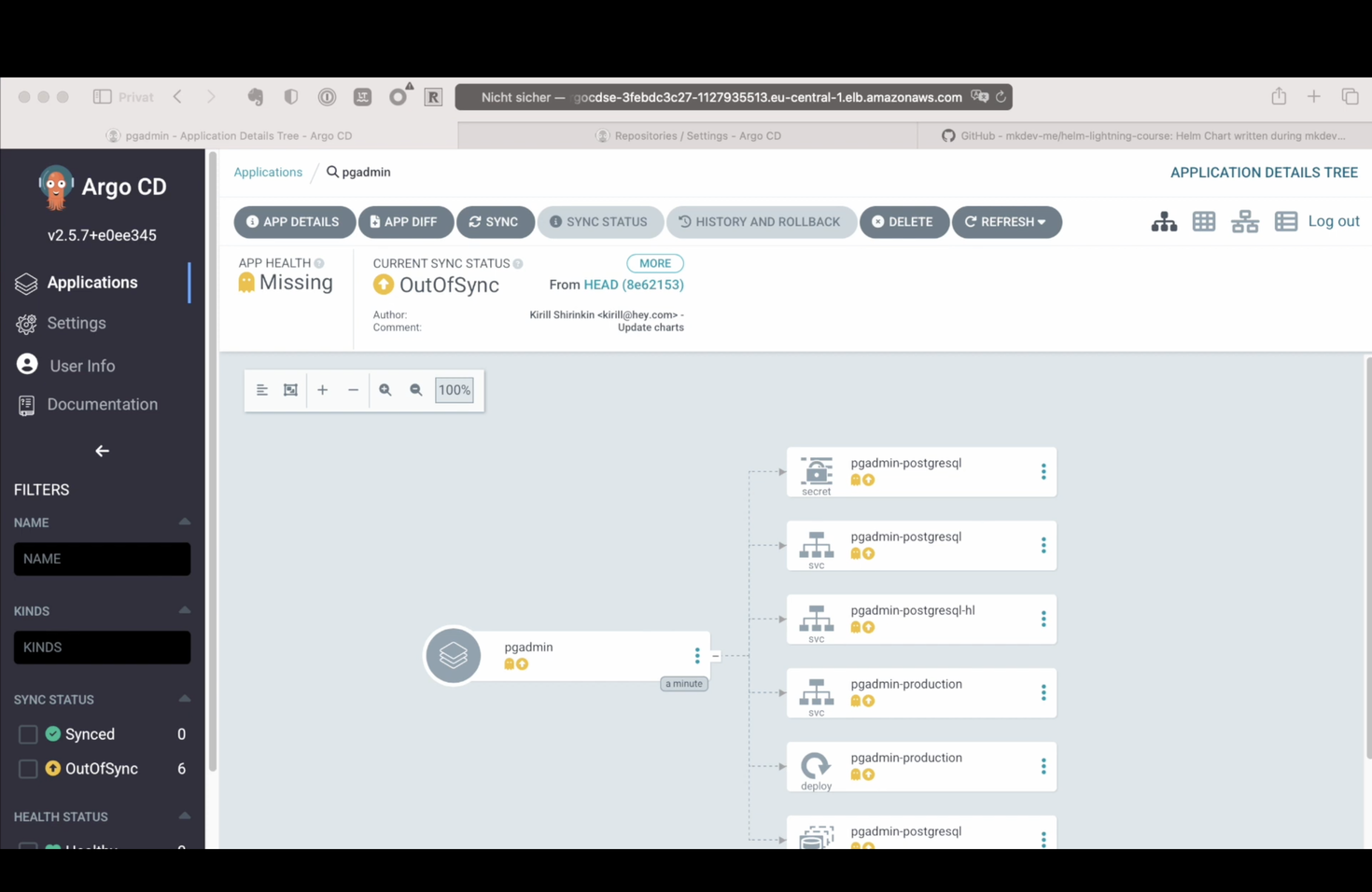
Argo CD detects that none of the resources within this repository exist in my Kubernetes cluster. When I click on the application tile, I see one of the nicest parts of the Argo CD interface - a list of all the Kubernetes resources within this application, together with its interdependencies and synchronization status.
I can examine the diff - Argo shows me in a nice way what exactly it will apply during the deployment. If I am happy with this diff - and I am happy - I can click on Sync button, and, leaving most of the sync options unchanged, proceed with the deployment.
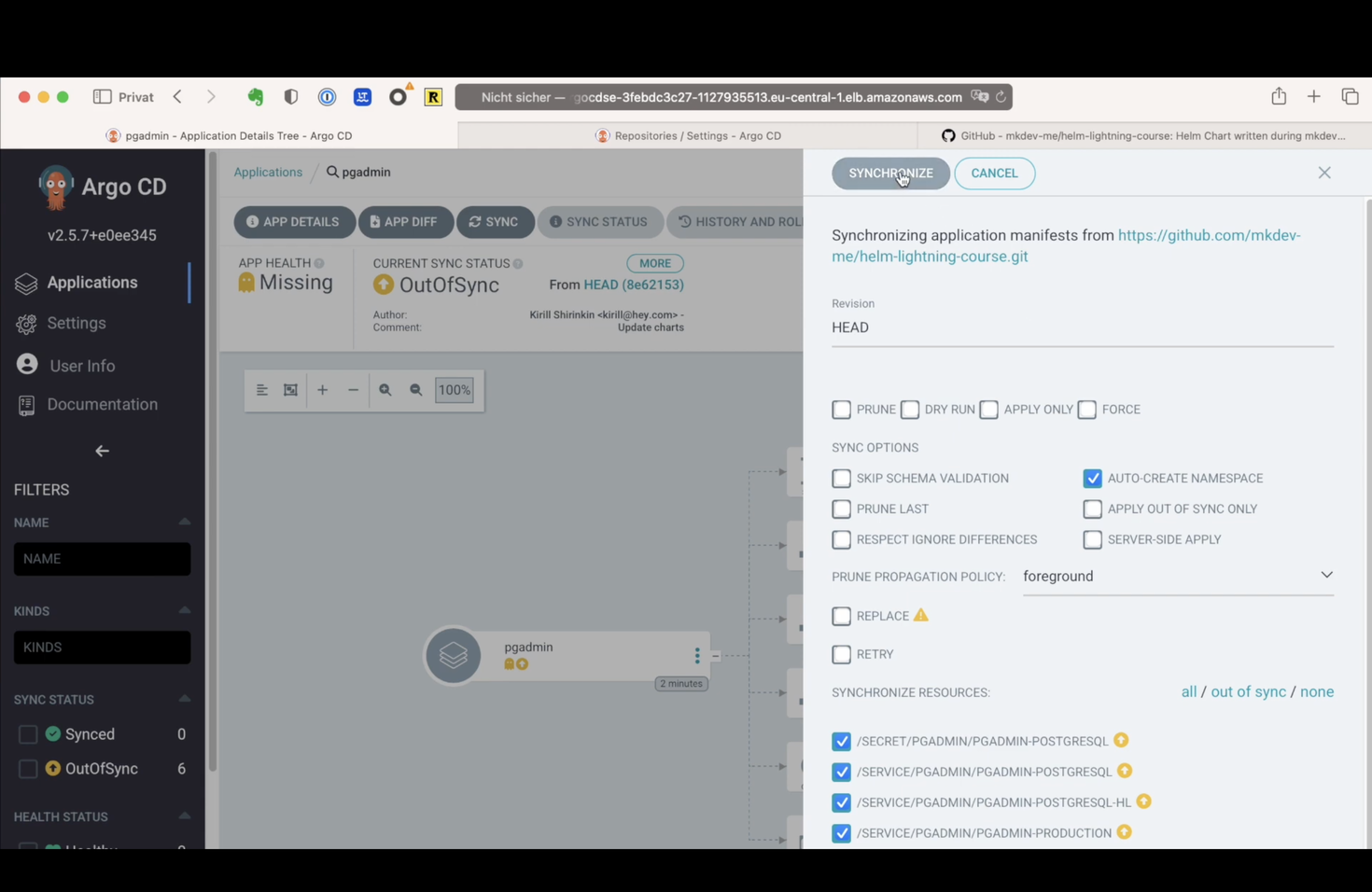
Unfortunately, it did not work as I expected - according to the error message, create Namespaces is not allowed in this project. That’s because I did not whitelist any of the Kubernetes resource types in my project configuration. Let’s do that.
I am going to the project configuration and my plan is to allow any resource types. In some cases, you want to restrict this - for example, maybe you don’t want to allow creation of Ingress objects within this project, or you only want to allow a handful of default object types. Now let me go back to our app and try to sync again.
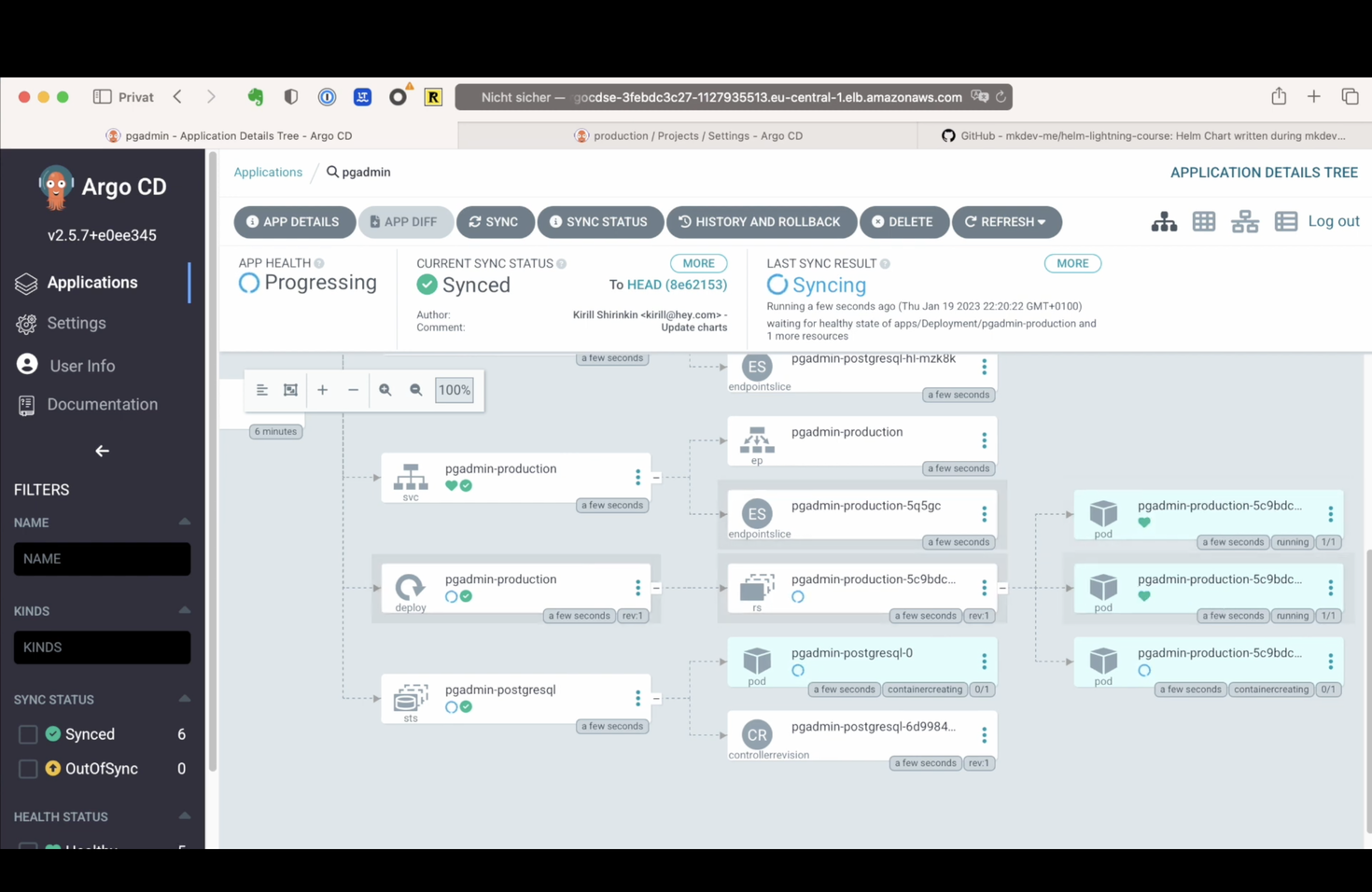
Now something really beautiful happens - we can see how Argo CD creates all the resources, and then automatically discovers all the related objects, like replica sets and deployments, and a post-upgrade Job. None of this is part of our Helm Chart, but the tool is smart enough to figure it out and give us some really nice interface. Of course, we are not supposed to spend too much time clicking around the UI, but when we have to do it, it’s good to have such a nice interface. I can even see the logs of the pods, as well as switch between different views for my objects. It even shows me some resource consumption metrics!
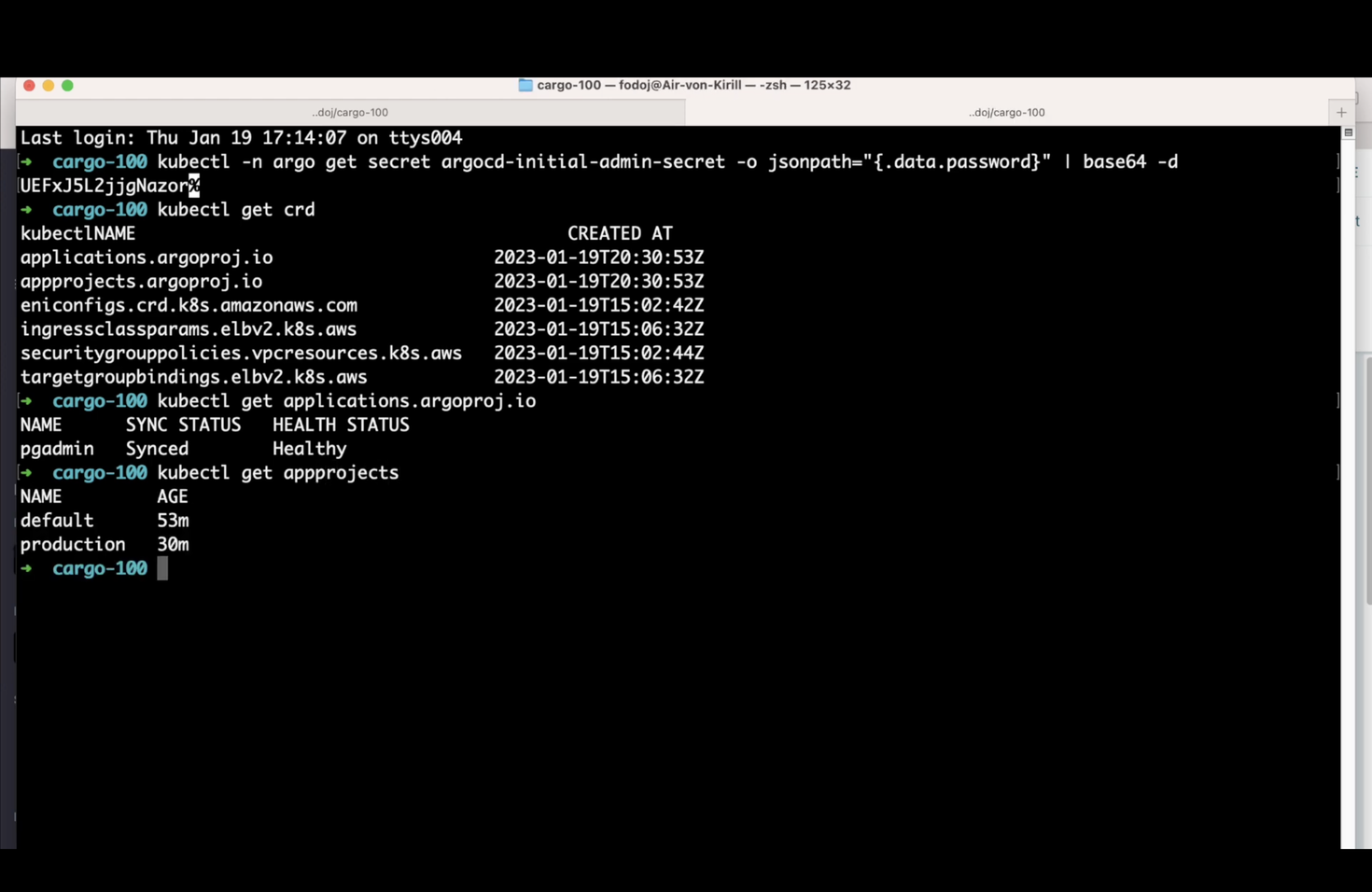
Our first Argo CD application is up and running. All of the configuration we just did is just Kubernetes objects - let’s quickly confirm that in our shell. We can store all of this configuration as YAML definitions and, well, deploy them with a Git Ops approach!
But what happens when we change our resources manually? And what happens when we push a change to the repository? That, as well as synchronisation options and windows, will be the topic of the next lesson.
Here' the same article in video form for your convenience:
Article Series "Argo CD Lightning Course"
- What is Argo CD, and why would you need GitOps?
- Argo CD Installation and Architecture
- Argo CD Clusters and Repositories - Two Core Components
- How to deploy Applications within Projects in Argo CD
- Argo CD Self-Heal, Sync Windows and Diffing
- Argo Ecosystem: Argo CD, Argo Workflows, Argo Events, Argo Rollouts, Argo Everything