Which database when for AI: Vector and relational databases in practice

In Part 1 of this two-part series, we introduced some example semantic and structured search data tasks, and connected these fictitious tasks to actual business ones. We also gave some theory behind database technology for AI, with special attention to the vector databases.
The second part of the series gets into the mechanics of both relational and vector databases as we consider solutions to our data retrieval tasks. Perhaps the most exciting, and---at the time of writing---least developed approach to information retrieval is to somehow combine structured search (e.g. with a relational database) and semantic search (e.g. with a vector database). We look at such an approach in solving our third task.
Finally, we give reflections and advice on which database technology to use when. We also point out some common "gotcha"s and venture a prediction or two on how databases for AI will develop in the near future.
Quick recap of example data retrieval tasks
For convenience, we give again our example information retrieval tasks from the first post.
Task 1 (semantic): Answer the question, "For which 100 butterfly races in the dataset race-descriptions.json did the swimmer have a good turn?"
Task 2 (relational): Answer the question, "What were the top 10 times in Germany for the seasons 2017-2018 and 2018-2019 for men in the 100m butterfly for the age group 40-44?".
Task 3 (relational and semantic): "What were the top 5 times in Germany for seasons 2017-18 and 2018-2019 for men in the 100m butterfly for the age group 40-44 for races featuring a good turn?"
Task 1 is flagged as "semantic" as solving it requires some computer representation of the meaning of "a good turn." A simple check of equality of text will likely not suffice, as the same meaning can be expressed in many different ways in natural language.
Task 2 plays to the strength of relational databases, as it can be answered by exact checks on relationships among entries in tables. The filters required to satisfy "for the seasons 2017-2018 and 2018-2019" can be achieved with exact checks on the date per race, and the retrieval of the top 10 times can be done by sorting the filtered records in descending order according to race time and taking the first 10. If our dataset also had different race types (e.g. 200m butterfly), age groups or genders, these also could be filtered using precise equality checks that relational databases can perform so naturally and efficiently.
Task 3 involves both semantics and structured search, as we are combining the structured search of Task 2 with a semantic search filter from Task 1. In our solution to this task below, we use such a combination, first filter for races featuring a good turn using vector embeddings and cosine similarity as introduced in the first blog post, Semantic Similarity, vectors and vector databases. Then we use regular relational database filtering and sorting to find the top 10 with good turns.
Solving our semantic and structured retrieval tasks
Solving the semantic search task 1: which 100m butterfly race had a good turn?
Task 1 with LlamaIndex's simple vector db
We choose the embedding model all-MiniLM-L6-v2, though the question of which embedding model is best for your business problem deserves serious attention.
An appeal of LlamaIndex is that demos of vector search can be written in a few lines of code, so it is worth a try, especially in the experimentation phase of Day 0.
Here's a code snippet to give you a sense of what semantic search involves with LlamaIndex. Please note that this snippet is not reproducible, as it uses both custom functions and ETL (or data preparation):
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import (
VectorStoreIndex,
SimpleDirectoryReader,
)
from dbs_for_ai.metrics import precision_score
from dbs_for_ai.llm_utils import find_sentences_with_match
embed_model_name = 'all-MiniLM-L6-v2'
embedding_model = HuggingFaceEmbedding(
model_name=embed_model_name
)
documents = SimpleDirectoryReader(llama_descriptions_datadir).load_data()
index = VectorStoreIndex.from_documents(
documents,
embed_model=embedding_model
)
retriever = index.as_retriever(similarity_top_k=10)
llama_index_task_1 = retriever.retrieve(TASK_1_QUERY)
llama_index_task_1_top_10_ids = []
for retrieved in llama_index_task_1:
retrieved_id = int(retrieved.metadata['file_name'].split('.')[0])
turn_text = find_sentences_with_match(retrieved.text, 'turn')[0]
print(f'retrieved_id: {retrieved_id}, similarity-score: {retrieved.score},\nTurn-next: {turn_text})\n')
llama_index_task_1_top_10_ids.append(retrieved_id)
with the first 4 hits being
retrieved_id: 11, similarity-score: 0.6189350675922203,
Turn-next: He had a great 1st turn, maintaining a strong momentum.
retrieved_id: 107, similarity-score: 0.6146611553355551,
Turn-next: However, he had a great 1st turn, propelling himself back towards the finish.
retrieved_id: 46, similarity-score: 0.6140113515138369,
Turn-next: However, he botched his 3rd turn, losing valuable time.
retrieved_id: 52, similarity-score: 0.6137856503016118,
Turn-next: He had a great 1st turn as he approached the wall.
We also calculated a retrieval metric, precision, based on a ground-truth list of indices of races that indeed featured good turns, ids_good_turn. The result is
precision_score(llama_index_task_1_top_10_ids, ids_good_turn)
>> 0.8
We can already see one of the errors from the sample results above: "he botched his 3rd turn" is not semantically similar to having a good turn. It's hard to say if having 80% precision on a small sample-size is good enough, as we haven't articulated a business metric with which to correlate this technical metric. Nevertheless it's a worthwhile discipline to already think about and implement metrics in experimental work, as it will become critical to moving toward developing and deploying your AI in Day 1.
Task 1 by throwing it at OpenAI
In our AI Strategy Guide, we trumpeted OpenAI's offerings as a fast and usually inexpensive way to get your business experimenting with AI. Unless there is a reason not to, such as data security or ethical concerns, throwing your problem at OpenAI and seeing what it produces is usually worth trying.
It's also usually worth seeing if OpenAI's GPT models can answer your question without having to provide additional data. When I first considered this toy task in Summer, 2023 when writing LMOps: Prompts just blew up your configuration space (and what to do about it), this was before the file-upload feature introduced at OpenAI's DevDays in August, 2023, so I was eager to try again.
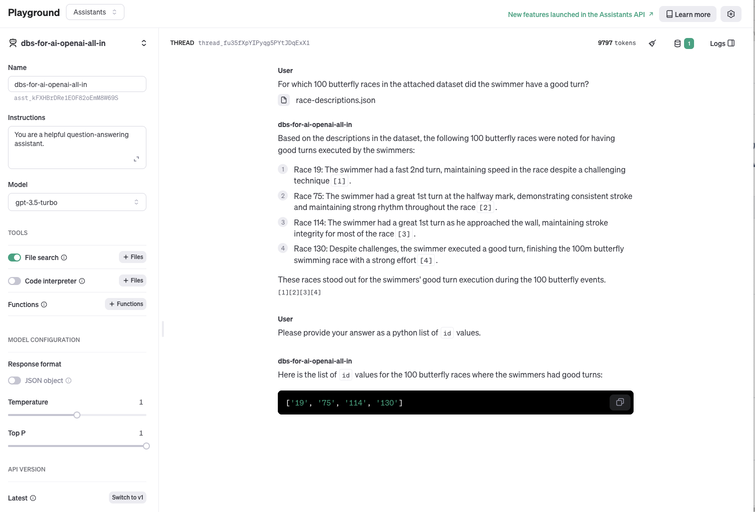
The precision score of this GPT-3.5-turbo assistant is 0.75.
Interestingly, for the one it got wrong (with id 130), the quoted description text is hallucinated. The actual relevant text is
On his first turn, he was long, which slowed down his momentum.
For the other, correctly identified races with good turns, the cited descriptions are also not word-for-word as in the uploaded data.
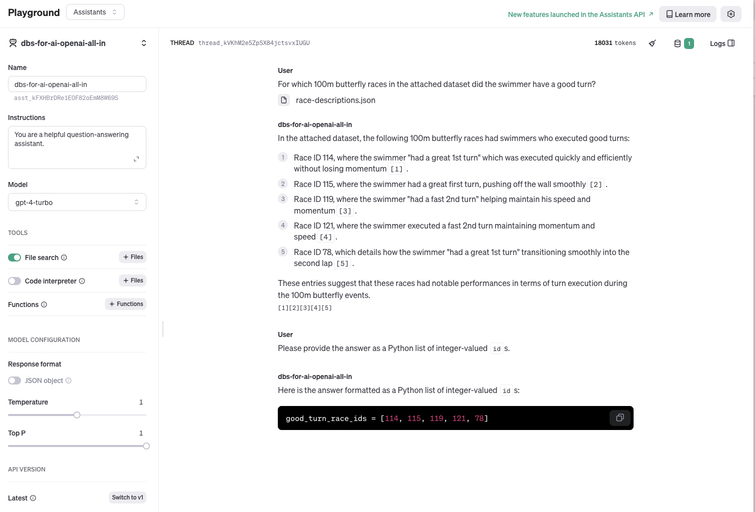
A GPT 4.5-turbo assistant achieves a perfect precision score of 1.0:
Solving the structured search task 2: what were the top times in 100m butterfly?
Task 2 with the relational database sqlite
Sqlite is the world's most widely used database technology, as it's lightweight and can be run on devices with minimal hardware specs. For our purposes, it's a quick way to experiment, but not really a technology choice to take you beyond prototyping unless you are deploying your AI on mobile devices.
Here's a code snippet showing how you can solve Task 2 about the top 10 times for seasons 2017-2018 and 2018-2019:
import os
import sqlite3
import pandas as pd
db_uri = os.environ['SQLITE_DB_URI']
conn = sqlite3.connect(db_uri)
sql = """select
schwimmer,
verein,
zeit,
ort,
datum
from swimming_result
where datum BETWEEN date('2017-09-01') AND date('2019-08-31')
order by zeit asc
limit 10;
"""
df = pd.read_sql(sql, con=conn)
df
The results we've already given above in the task description section from the first post.
Note that the date range between September 1, 2017 and (inclusive) August 30, 2019 reflects domain knowledge about swimming seasons in Germany.
Such question or business-specific details are often decisive. If this is the case for your data search needs, then be sure that your database technology choice naturally supports precise queries, e.g. over time ranges, and beware of duct-tape hacky-fixes required by databases lacking such a feature.
You may have noticed that I do not filter on gender or age-group in this query. This omission is purely because of the manual nature of data gathering: if I had manually collected more results from the German Swimming Association masters website, then such additional filter criteria would be both necessary and easy to incorporate in our retrieval query.
Task 2 by throwing the problem at OpenAI
As with Task 1, let's try a GPT assistant on Task 2. We're not playing to GPT-strengths here, but these generally keep getting better, so it's usually worth trying even if you were disappointed with results a few months back.
To give GPT assistants a fighting chance, we tell it when the swimming seasons 2017-2018 and 2018-2019 start and end. We also specify that we want results across both seasons, not individually (due to trial-and-error prompt experimentation).
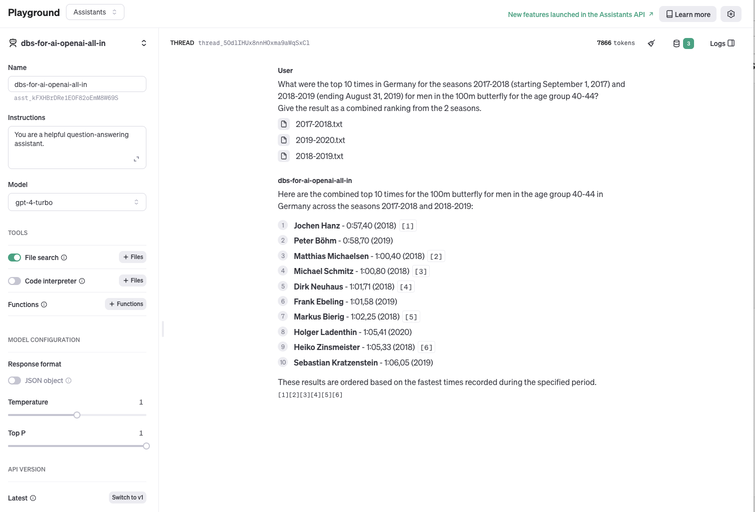
This GPT 4.5-turbo assistant get's 6 of the 10 entries correct for a precision score of 0.6. Two of the missed top-10 times were additional results from the two fastest swimmers. The final 3 results found by the GPT 4.5 turbo assistant, however, are wrong, as they are slower than other races in the same time-period (including a race by the blog author).
An additional request of the assistant to also include multiple results from a single swimmer (not shown) bumped the precision score up to 0.7 from 0.6. Just before publishing this post, OpenAI released GPT-4o. We re-ran Task 2 through it, with the result being a precision score of 0.8, with the incorrectly received races results both in November, 2019, which is outside of the specified date range.
We have done little prompt engineering or other tricks to get better results out of LLMs, as it typically only makes sense to pursue the all-in OpenAI strategy if it works convincingly out-of-the-box. Otherwise, you'll be debugging natural language in a webconsole (or IDE using their API) in the hopes that somehow, something will work well enough during development, and then continue to do so over time.
The out-of-the-box OpenAI performance is poor enough that we don't even try the combined semantic and structured Task 3 with it.
Solving the combined structured and semantic search task 3: what were the best times for 100m butterfly races featuring a good turn?
Is it too much to ask for a data retrieval system that can deal with fuzzy, semantic search as well as structured, SQL-like queries and combinations of the two? Or is this just a database version of the proverbial German egg-laying-wool-providing-milk-giving-cow Eierlegende Wollmilchsau?

As we've seen already, there are good solutions for semantic and structured search separately, so as long as you have access to the right expertise, this dream can be realized for your business problem by writing custom code and pipelines that combine the two as needed.
The amount of custom code to patch together structured and vector query databases is likely to get less and less over time, however, as providers of structured databases are offering vector (and hence semantic) search on top of structured search.
Below we consider how this looks with the pgvector extension of the relational database.
Task 3 with the pgvector extension of PostgreSQL
If you are already using PostgreSQL, then it's likely a good time investment to consider the vector-search extension pgvector before jumping to a dedicated vector database.
And if you and your team is using Postgres, then you're likely more comfortable and productive writing declarative SQL code rather than imperative python. Your team and your data are, in my opinion, the two biggest assets of any data or AI team, so it pays to play to the strength of both.
Below is a snippet of how a solution to our combined semantic and structured search can look using the python library psycopg to interact with a Postgres instance. As with the other two code snippets, the intent is to give you a feel for the solution space, even though the code doesn't run as is without custom dependencies and ETL scripts.
from dataclasses import asdict
from sentence_transformers import SentenceTransformer
import psycopg
from dbs_for_ai.etl_pgvector import DbCredentials, make_experiment_table_name, embed_as_str
embed_model_name = 'all-MiniLM-L6-v2'
embed_model = SentenceTransformer(embed_model_name)
query_vector = embed_as_str(sentence=TASK_1_QUERY, embed_model=embed_model)
embed_table_name = make_experiment_table_name(stem='dev.race_description', model_name=embed_model_name)
with psycopg.connect(**asdict(db_credentials)) as conn:
similarity_threshold = 0.60
task_3_pgvector_sql = f"""with similarity as (
select
id,
content,
1 - (embedding <=> %s) as cosine_similarity
from {embed_table_name}
),
cutoff_similarity as (
select * from similarity
where cosine_similarity >= {similarity_threshold}
)
select
vec.id,
tab.schwimmer,
tab.zeit,
vec.content,
vec.cosine_similarity,
tab.datum
from cutoff_similarity as vec
left join dev.swimming_result as tab
on vec.id = tab.id
where datum BETWEEN date('2017-01-01') AND date('2019-12-31')
order by zeit asc
limit 5;"""
cur = conn.cursor()
cur.execute(task_3_pgvector_sql, (query_vector,))
task_3_pgvector = []
print(
"Query: What were the top 5 times in Germany for seasons 2017-18 and 2018-2019 "
"for men in the 100m butterfly for the age group 40-44 for races featuring a good turn?\n"
)
for row in cur.fetchall():
content = row[3]
turn_text = find_sentences_with_match(content, 'turn')[0]
record = dict(
retrieved_id=row[0], similarity_score=row[4], schwimmer=row[1], datum=row[5], time=row[2], turn_text=turn_text
)
print(
f"retrieved_id: {record['retrieved_id']}, similarity-score: {record['similarity_score']}, "
f"swimmer: {record['schwimmer']}, timedate: {record['datum']}"
f"\nTurn-next: {turn_text}\n"
)
task_3_pgvector.append(record)
Something to note is that we've chosen a similarity threshold of 0.6. With structured search, there is typically no need to pick thresholds or otherwise find good choices of parameters. In this case, however, we need a threshold to restrict how well the race-descriptions match the question text before we then combine these race descriptions with the top times for the dates in question.
This question of which similarity threshold to choose is a fundamental one for all RAG (retrieval augmented generation) approaches using vector similarity. If we set the similarity threshold too low, then there's the risk of too many records being returned, meaning the LLM performing generation will be basing its response on incorrectly retrieved information. If too high, then the LLM won't have all the relevant (local) data upon which to generate a response.
There are techniques for mitigating these risks, though I have yet to see a robust presentation of them in blogs or product documentation.
Wait, don't vector databases support structured search?
There's a great German word to answer this question: "jein", which is a combination of German for "yes" ("ja") and "no" ("nein").
The vector databases I know of mostly have the option of attaching metadata to each vector in the database plus some relatively simple filtering logic that can be applied to the key-value combinations of metadata entries. For example, Pinecone and Vectara give users the option of filtering metadata via combinations of string equality (e.g. 'doc.datum' == '2017.09.01') and numerical inequalities.
Another way is what's being called "hybrid search", which in this context refers to a mix of vector similarity and keyword search.
The first of these, filtering on metadata key-value pairs, is more or less a re-implementation of what MongoDB and other key-value store databases offer. The second, combining vector-similarity and keyword search, is essentially a mix of vector-similarity with what ElasticSearch and the like do.
Or we could go old-school AI for Task 3
A different approach from the not-so-distant AI past is also worth mentioning. Before vector databases captured the attention they now possess, data scientists would use embedding models and other NLP techniques to create features, e.g. for classification models. The question of whether a race-description describes a good or bad turn equates to sorting each description into two classes, good-turn or bad-turn (and possibly a third bucket if no turn description is present).
With this approach, a predictive classification model, e.g. using logistic regression, gradient boosted trees or possibly a neural network, not cosine-similarity, would be used to filter the races for ones featuring a good turn.
A peek under the ETL (“extract, transform, load”) hood: loading data into vector databases
I like to think of data engineering as data plumbing, and AI as data wizardry. While this language might make AI work sound cooler than data engineering work, my intention is the opposite. No magician will stay in business long if their toilets don't flush and their drinking water teems with E. coli. bacteria.
The same holds for building on top of vector or relational databases, e.g. to perform semantic search. We've decided not to publish all of the code behind these demos, as we're proud of our plumbing and don't have enough market share (yet) to give it away for free.
Nevertheless, to evaluate which database technology is best suited for your semantic search or other AI use case, it's important to know what loading data looks like in practice, as this will strongly influence how you manage your data pipelines to ensure you're ticking important boxes, such as writing pipelines that
- provide a good-enough developer experience for your team,
- can be tested,
- support data versioning, and
- support data governance, including master data managment.
For pure semantic search tasks, the new vector database niche providers make it easy to get data into vector databases and start using it. Pinecone's quick-start on semantic search has you spinning up a vector database, encoding a corpus of Q-and-A from Quora as vectors, inserting into the database, and running semantic queries on it in about 70 lines of code. With LlamaIndex, it's down to six lines of code, though with OpenAI's service to do the vector embeddings rather than an open source HuggingFace SentenceTransformer model as with Pinecone.
For Day 0 experimentation or early Day 1 prototyping, these quick-start options can be a low-invest way to iterate quickly.
Once you reach the point of needing data governance and management such as integrity constraints, versioning, testing, or access control, it's largely up to you to either build your own data governance management on top, or find some other solution. The same holds for an all-in-OpenAI approach to loading into and managing vector databases.
Loading data into LlamaIndex's VectorStoreIndex
A selling point for LlamaIndex is how quickly you can get started and experiment. The code snippet for loading our embedding vectors into the (in-memory) VectorStoreIndex shows (it's 3 lines of code in the basic usage tutorial).
For your convenience, we reproduce below the relevant lines of code for loading embedding vectors with LlamaIndex.
# Enforcement of embedding model's maximum sequence length
st_embedding_model = SentenceTransformer(embed_model_name)
for a_doc in documents:
enforce_text_length_expectation(text=a_doc.text, embed_model=st_embedding_model, tokenizer=tokenizer)
# load vectors into vector db
index = VectorStoreIndex.from_documents(documents, embed_model=li_embedding_model)
The main components are
Checking that the text being encoded doesn't exceed the maximum length of the embedding model with
enforce\text\length\expectation. Without such a check, many implementations will silently truncate your text to its maximum length, meaning you have a silent failure mode on your hands. We don't implement any remediation in case our text is too long, but there are several ways to handle this situation.Calculating vector embeddings and loading into the database with
index = VectorStoreIndex.from\documents(documents, embed\model=li\embedding\model).
Regarding our pipeline quality criteria,
developer experience is great in initial experimental, Day 0 work, especially if you are completely new to vector databases. My experience, however, is that once you move away from this high-level few-lines-of-code cases, the developer experience of the LlamaIndex abstraction worsens.
the convenience of few-line-code high-level implementations often makes testing a challenge, as step 2 above for example combines two separate functions, each with their own (in my opinion) distince interface.
data versioning is a bit silly as implemented above, as the database is in-memory, but there is a mechanism to persist the database to disk as a JSON object. As an object on disk, you could version it using dvc, though I question how meaningful it is to track and inspect diffs of vectors represented as 300+ long tuples of numbers. Record level versioning is also in theory possible via metadata attached to each vector.
data governance is possible, though perhaps not very natural. Here the question is not so much data governance features, but how natural or unnatural it is to integrate LlamaIndex's vector database approach (i.e. abstraction) with dedicated data governance tooling.
Loading data into PostgreSQL with the pgvector extension
PostgreSQL as your vector database is a potentially attractive option if you and your team are already using Postgres, as you can carry over almost 1:1 your developer experience, testing, data versioning and data governance processes and artifacts to vector embedding work.
Here's a modified snippet from our pgvector ETL python module. It has the same basic components as the LlamaIndex example above, with one notable difference being that we've split out the creation of the embedding vectors and their loading into the database.
def etl_race_description(
source_path: Path, conn: psycopg.Connection,
embed_model_name: str, environment: str
) -> None:
table_name = make_experiment_table_name(
stem=f'{environment}.race_description', model_name=embed_model_name
)
# <some omitted data mgmt code here>
embed_model = SentenceTransformer(embed_model_name)
tokenizer = AutoTokenizer.from_pretrained(embed_model_name)
with open(source_path, 'r') as fp:
descriptions = json.load(fp)
# Insert descriptions
cur = conn.cursor()
for a_record in descriptions:
enforce_text_length_expectation(
text=a_record['description'],
embed_model=embed_model, tokenizer=tokenizer
)
embedding_as_str = embed_as_str(
sentence=a_record['description'], embed_model=embed_model
)
parametrized_query = f"INSERT INTO {table_name} (id, content, embedding) VALUES (%s, %s, %s);"
cur.execute(
parametrized_query,
(a_record['id'], a_record['description'], embedding_as_str)
)
cur.close()
conn.commit()
With PostgreSQL's pgvector extension, the strict number of lines of code to lead vector data in isn't much more than with the above quick-starts, but if you're coming more from the application development or machine learning world, rather than database or data warehousing world, it might seem a steeper learning curve.
A potential benefit, however, is that the data integrity checks, validation and governance that you may already have in ETL for your database or warehouse won't need to be built from scratch. As an example, I could test this vector embedding ETL code using the same Postgres testing pattern I use for other purposes.
A few additional points to note are
- Vectors need to be passed as strings during insertion, though they are not stored internally as strings.
- We don't consider performance or cost considerations at all, though these are important points.
Conclusions
The "when" of database technology
We've seen that GenAI and vector similarity can give some quick, LGTM (“looks good to me”) query results with minimal coding and infrastructure. This gives a concrete example of how AI advances can accelerate your experimentation and product-market fit research in your strategy building phase of Day 0.
There are risks to this strategy. If your leadership does not understand why throwing vector search on top of structured data is a short-cut for experimentation and product-market fit purposes, you may struggle to get the resources you need for robust, reliable data infrastructure when you move on to Day 1 ("releasing first AI product") and beyond.
At the risk of simplification, semantic similarity with vector databases are usually well-suited when
your data sources are primarily free text
the relevant answers depend on the context of surrounding words (or sentences)
the relevant answers have similar meanings but highly varying presentations (e.g. word-order)
And poorly suited when
- your content contains domain-specific terminology (e.g. in swimming a "long turn" is bad, yet a "long stroke" is good), or product names that either do not exist or have multiple, competing meanings in general usage, such as
- a company whose main product is called "Time"
- "X", the social media platform formerly known as "twitter"
- the relevant answers depend mainly on specific keywords
- the relevant answers depend critically on filtering logic
- the relevant answers require combining data across sources (e.g. with joins)
Furthermore, based on my own experience (and that of colleagues), semantic similarity is in general a poor fit when either your query or the knowledge base over which you are searching consist of short texts.
It's not quite true to claim that structured search, e.g. with SQL on a relational database, is a good fit where vector databases fall short, but it's also not far off.
The first 'ill-fit' situation of domain-specific terminology is a challenge for all information management systems. For relational databases, the solution is generally to ensure your business data model captures this domain knowledge (e.g. with a product-name field). For embedding models we already mentioned the approach of custom pipelines to handle domain-specific vocabulary differently. There's also the option of training domain specific language models, though this route invovles costs of data-preparation, compute and having the expertise to do this well.
There's still no free lunch, but there are some new menu items
Even in the above-referenced Star Trek scene in which the ship's counsellor Deana Troi asks the computer about the meaning of an unknown foreign term, the response requires further probing to disambiguate among a 7th dynasty emperor on Khanda 4, a frozen dessert on Tasma 5 or other possible galactic meanings.
This behavior is common for human-human queries, as well.
Alice: "When are you back from vacation?".
Bob: "Thursday, May 2nd."
Alice: "So you're back in the office then?"
Bob: "No, I arrive back on the 2nd. I'm back in the office on Monday, May 6th."
The point is, we rarely know in advance what precise form a query should take to elicit the information we need. One reason I see for the viral growth of ChatGPT, which technologically isn't much different than the underlying LLM that did not go viral, is the UX of iterating on your question formulation until you have found the formulation that yields the answer you need.
The interactivity of ChatGPT sharpens human thinking about what question we are actually trying to answer.
This free-form interaction is not usually what data engineers strive for in building data pipelines and business intelligence tooling, where structured transformations and queries make possible two important components of any data system: governance and testing.
As we've seen, off-the-shelf there isn't yet a solution offering the best of structured, relational and free-form, vector-similarity queries, let alone doing this in an interactive way. I hope it's also clear, though we haven't shared much detail, that it is indeed possible to combine existing technologies to get close to this dream for specific business needs.
There's a saying "Don't throw the baby out with the bathwater" (yes, it's brutal when you think about it, but about on-par with Grimm's actual stories---not the Disney remakes---or Highland Fairy Legends). Applied to (Gen)AI and databases, the counsel is to not discard what has been working for you just because there's something new and shiny.
The apparent good news is that many existing databases have been adding vector storage and search. I say "apparent" only because I haven't yet personally tested each of these. If you have, please let us know!
So, if your company or team is currently using any of
- PostgreSQL
- Oracle
- Redis
- Neo4j
- MongoDB
- Elasticsearch
- DynamoDB
- Databricks
- BigQuery
- Apache Cassandra
then it's likely worth trying their offering before adding an additional database technology to your stack.
Reflection: It's not just about getting one right answer
A common mistake in discussions about GenAI (and regular AI) can be called "LGTMIANGE", which is an acronym for "Looks Good To Me Is Almost Never Good Enough", and could (should?) be pronounced "ell-gee-tee-em-iangee". We see this phenomenon in its negative version with the gotcha-style examples about what ChatGPT or its cousins get wrong, like Google Bard's botched answer about the James Webb telescope in its marketing demo. The positive version is usually a few cherry-picked cases that do indeed look good. This practice can lead to wrong business decisions about the utility and risks of AI in business applications.
There are two reasons why cherry-picking LGTM (or not LGTM) can lead to mistakes in business:
The business value or risk is typically in the aggregate, not just individual cases.
Success or failure of an AI application needs to be precisely defined to be assessed, not just "look good."
On the first point, there will of course be some business applications that require zero tolerance for error. More typically, what matters is performance over many cases, like the percentage of questions that your AI chatbot is able to handle correctly over all requests per month.
On this second point, a challenge in truly getting value from AI is to ensure it works beyond impressive demos. A management sponsor might like your demo showing how your semantic search powered chatbot can answer questions enough to support your go-live work (from "Day 0" to "Day 1"), but unless you have precise technical and business metrics that show month after month that your AI application is profitable, management has little bottom-line reason to pay for your AI. LGTM to evaluate performance in bulk over longer periods of time simply does not work.
Final "gotcha" warnings
As with prompt engineering, semantic search adds extra volatility to your problem's configuration space, as the phrasing of your question can have a marked effect on the results, i.e. language syntax, not only numerical parameters or precise query combinations, need to be evaluated as part of your retrieval development and testing. In the example above in the section A very short introduction: the mathematics behind semantic similarity, vectors and vector databases, if we changed from query string from "Was there a good turn" to "Did the swimmer have a good turn?", then the turn-query is more similar to the description of a start than to either of the two turn description texts, giving further evidence for LGTMIANGE.
As with any tech-buzz topic, GenAI brings with it the risk of demo-ware in the bad sense of the word, namely products that make demos easy ("get it running with just 5 lines of code") but actual problem-solving hard, if not impossible. In other words, beware of new technology that makes moderate tasks easy and hard tasks impossible.
Wrap-up
What is the future of vector and other databases for AI? It's alway risky to make predictions, especially about the future, but if I were to guess, it would be that niche players riding the GenAI wave will lose ground, as the prime movers of GenAI, such as OpenAI, take over more and more of the easy use-cases (like the RAG-ready OpenAI Assistants API shown above in the throw-your-problem-at-OpenAI example). For more challenging use cases, the established database players are moving in as well, leaving less and less use-case real estate for both proprietary, closed source offerings such as Pinecone and Vectara, and also open source frameworks like LlamaIndex and LangChain.
In the now, however, the recent advances mean that there are more database technologies to choose from, some of them which are tasty, nutritious and reasonably priced, others not so much. What's needed, then, is the expertise, in-house or external, to help your business choose the right (combination of) database technology, and then weave them together for your data needs.
P. S.
The people behind LlamaIndex have done some valuable work that has enabled a lot of developers to get their hands on vector search and RAG.
I mention this before sharing a screenshot showing how retrieval is not a simple problem, even for some of the people developing retrieval software:
Article Series "Which database when for AI"
- Which database when for AI: Are vector databases all you need?
- Which database when for AI: Vector and relational databases in practice