How to Configure OpenShift 4 Cluster Nodes: MachineConfig Operator and CoreOS

In the previous article we saw 3 core features of OpenShift that make cluster management and operations not only easier, but in some regards completely different from what you might be used to.
One of those features is the usage of specialized Container Operating System for every node in the cluster. In case of OKD - the open source OpenShift version - this system is Fedora CoreOS. In the enterprise flavour of OpenShift RedHat is using RedHat CoreOS.
Two primary features of this operating system is that it's immutable and it's sole purpose is to run containers.
This functionality is enabled by two open source technologies.
One is called ostree and another one is called Ignition.
Ostree makes your server managed like a set of filesystem layers and Ignition allows you to customize your server a bit similar to how you would customize it with configuration management tools.
If this sounds confusing, then check out a video that I made about both of these tools and Fedora CoreOS in general. It will help to better understand what we are about to learn in this article.
Both ostree and Ignition are rather low level tools. You need a lot of plumbing to make them work for you. Let's see how this plumbing is implemented in OpenShift.
I've installed a new cluster for this article, OKD version 4.6. You might notice, that Cluster Setting page looks a bit nicer, compared to what was before.
OpenShift cluster is automated and managed by a set of Cluster Operators, where each Operator is responsible for certain parts of the cluster configuration. There are operators for monitoring, logging, networking and so on.
The one that is taking care of configuring the cluster nodes is called machine-config.
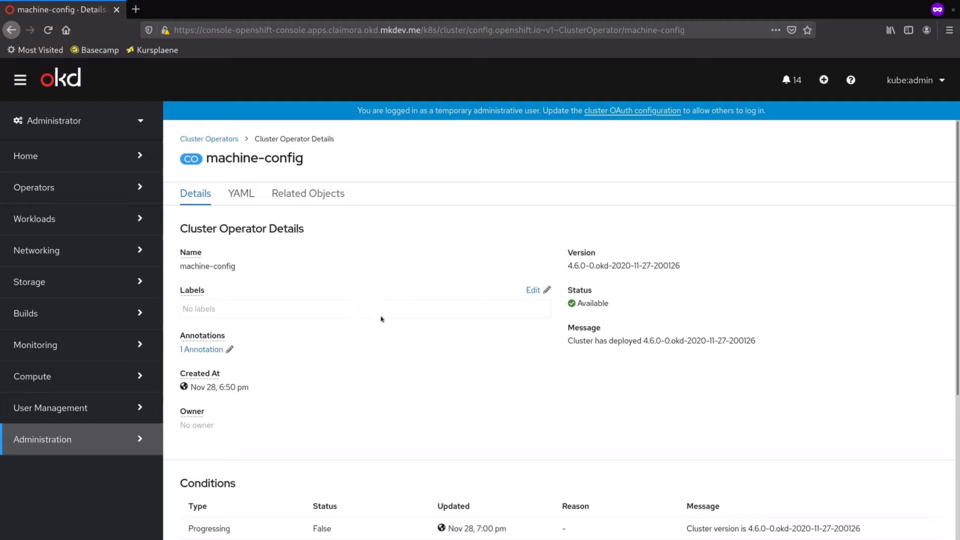
MachineConfig operator takes care of patching and applying changes to the cluster nodes. I will talk about how it works on a high level.
MachineConfig Cluster Operator provides us with two new custom resources. We can see both of them in the Compute tab on the left.
First one is called MachineConfigPool.
We can see that there are 2 config pools out of the box - one for workers and one for masters.
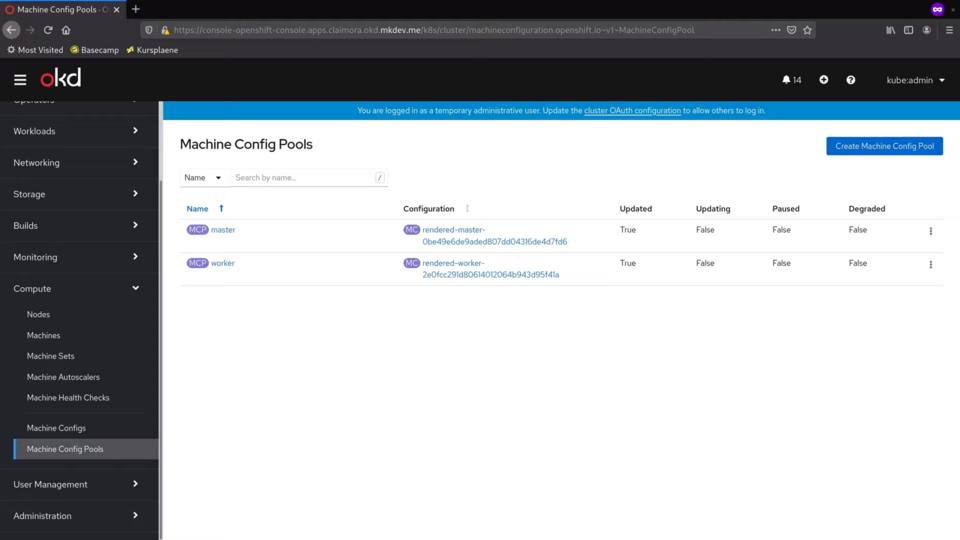
Let's check the one for workers.
Inside the machine pool we can see how many machines are part of this pool. Machines are selected based on node labels, that we can see down here.
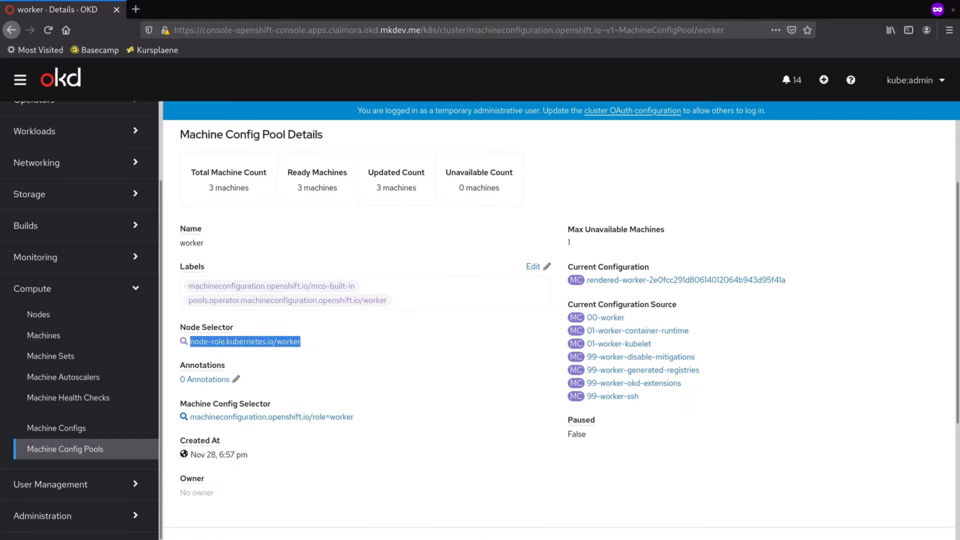
Each pool has a number of associated Machine Configs, that we can see in the Machine Configs tab.
OpenShift cluster comes with a bunch of MachineConfigs both for masters and for workers. Let's check the one called 00-worker.
Each MachineConfig config is basically just a wrapper around Ignition configuration, that is then applied to the node. The out of the box machine configs contain critical cluster configuration.
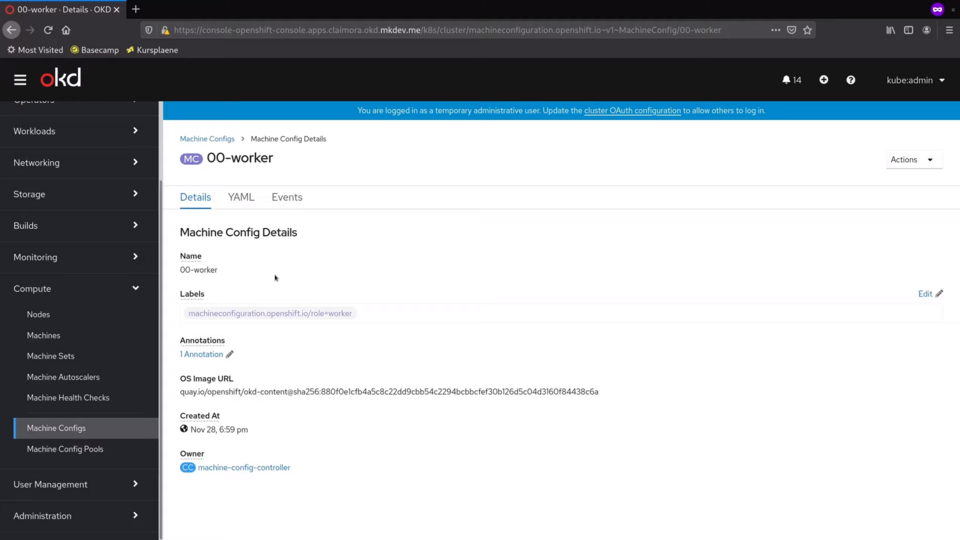
If we check the YAML of this one, we will see that it defines things like container storage configuration, cluster CAs, cgroups and network configurations, a number of systemd units and so on.
Even though almost everything in OpenShift cluster runs inside containers, there is still some configuration that needs to be done on the node. All of this configuration is defined and automated here, in MachineConfigs.
Every cluster node is part of a machine config pool. The pool defines for which nodes it applies.
Each machine config pool has multiple machine configs, selected by the label.
Each machine config wraps around ignition configuration.
When you change any machine config in the config pool, MachineConfig Operator re-renderes all the machine configs it has, prepares the final single Ignition configuration and does a rolling update of all nodes to match this configuration.
The update is done by rebooting every node, one by one, even for the smallest changes. That's how ostree works - it needs to build a new filesystem layer and boot into this layer on the next server restart.
Let's do something very common, something, that you actually might not do for OpenShift clusters: adding a new authorized ssh key to every worker node.
I am going to click on the plus botton over there to import the YAML file.
I am doing it only for demonstration purposes - you must store all of your YAMLs in version control and apply them automatically.
Let me paste the new MachineConfig.
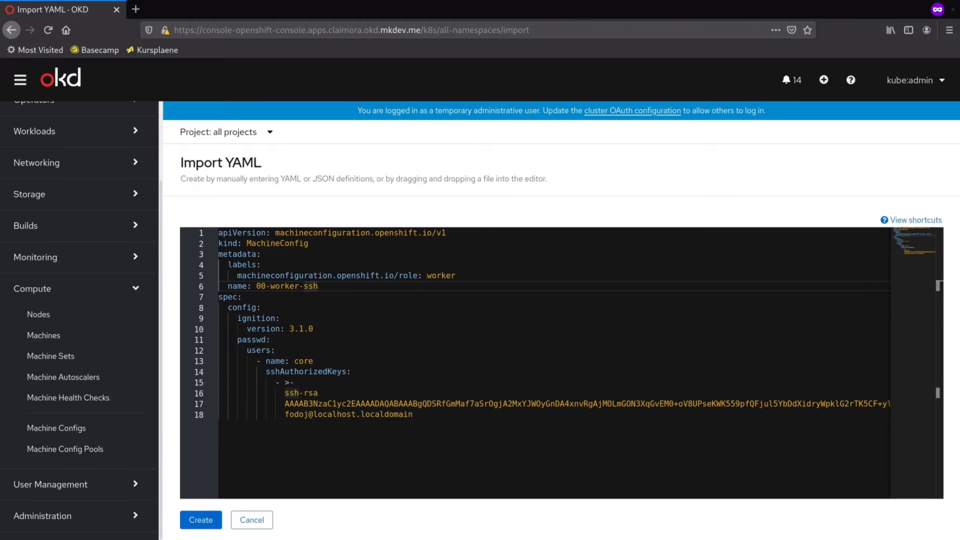
I am setting the name to 00-worker-ssh. The numbers in the name force the order in which all machine configs of the pool are merged into one another.
I am also setting a label, that will help MachineConfig Pool to discover this machine config.
Finally, inside spec section I define the core user, with my ssh public key. Now let me save it.
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: worker
name: 00-worker-ssh
spec:
config:
ignition:
version: 3.1.0
passwd:
users:
- name: core
sshAuthorizedKeys:
- >-
ssh-rsa
AAAAB3NzaC1yc2EAAAADAQABAAABgQDSRfGmMaf7aSrOgjA2MxYJWOyGnDA4xnvRgAjMOLmGON3XqGvEM0+oV8UPseKWK559pfQFjul5YbDdXidryWpklG2rTK5CF+ylIktMpJu7ggw64crMpSF4IQXpNI1QoYt8bWJJPlOqd1m48+nGzYZo/GOe/Tf2sBoy6WvsxqDiwHWorROoUZz/m1iuNh4Fmh55vpbhdgpSq6duGxv6P9rYpmyh153TdhB8LOZtGTQeunn33OM1O4dkHDp15LFo5sUBYAwnXMXqceC5vys5cMgtwjR9fRZkGiiz1+rfQmE+guxwVtn3dpfVYed9hm/5OLPkXFkWlf1IRot14Ye/kJPYbqVHYux6EbfC4Je3wK0Xu1vxNwVYhH0rXC7ScPk/WnmvQLJlDMRTRHdrJq97O2FX8sV2s8TewD3FH4BpcPjL6dXmYh+rNxZ1hsUdzaPE1QtftdMcu661FW/+upCeaoqdOuXj7IrTQNx8Orqpv0YfrMDDagFMauNkTdTMsS/sxrc=
fodoj@localhost.localdomain
Right after I save it, MachineConfig operator will pick this MachineConfig up, make it part of the pool, force the pool re-render the configuration and start applying this new configuration to every worker node.
If we open the MachineConfigPool list, we can see that it's already in Updating status. You should be really careful with changing MachineConfigs, because each change will result in a rolling restart of every cluster node.
If we check the list the cluster nodes, we will see that the currently updated node had scheduling disabled. OpenShift makes sure, that cluster updates are not disruptive to the platform users as much as it can.
Even thought, as you can imagine, your applications must be highly available to survive such updates without downtime. If your application is running only inside a single pod, it will be down because the node where this pod is running will be restarted during the cluster upgrade.
If I open the rendered file, then I will see all MachineConfigs of this pool merged together, including the newly added ssh key.
If we check the status of the pool, we can see that one of the machines is already updated.
Let's enter this machine via the built-in terminal and verify that my public key is available inside.
My cluster nodes are located in private network and I can not access them over the Internet. But what I can do is to use the browser based Terminal in this OpenShift console.
If I check the home directory of the core user, I will find my public key in there. Actually, my key is specified twice.
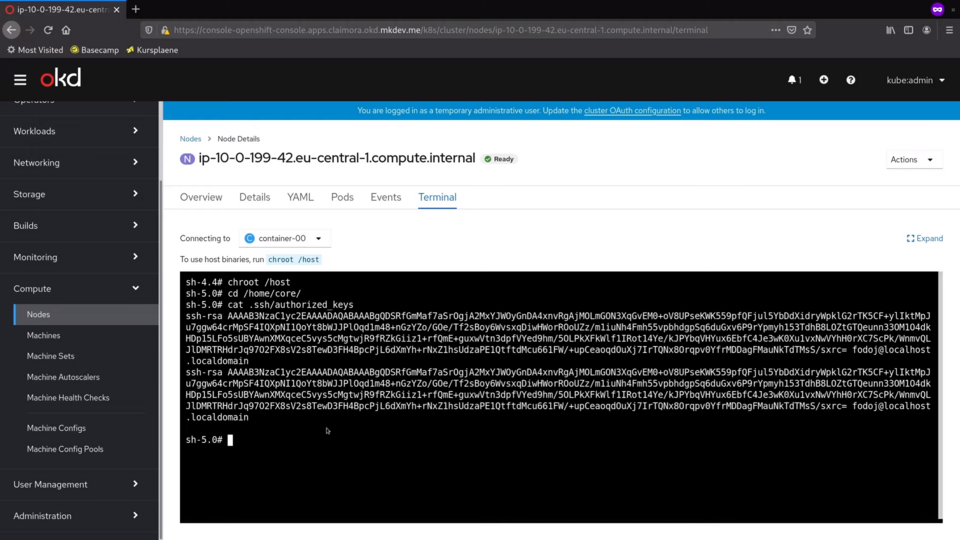
The reason for this is because I also specified the ssh key during the cluster installation. Clearly, Igntion, combined with MachineConfigOperator, does not care about idempotence - and this is one of the reason why you should not use this configuration approach too often.
If you are thinking that this MachineConfig API is a bit inconvenient and hard to use, then you are right. Ignition is a very minimal configuration management system and it's hard to do any complex configuration with it. The forced rolling restart of every node also could be a problem if you run none-HA applications in your cluster.
But the whole idea of OpenShift 4 and the Container Operating Systems is that you are not even supposed to do a lot of host-level configuration.
Everything you run, should run in containers. Even the SSH access should be discouraged as much as possible, and OpenShift has all the tools built in to make sure that you don't need to login to the node unless something is really badly broken.
Still, MachineConfig operator is an essential part of the OpenShift Cluster and it's an interesting way to automate the inevitable host-level configuration of your clusters. Even if you dont use it much, you have to know that it's out there and what it does.
Cloud Native consulting: regardless if you are just getting started, or looking for a big shift from the old ways to the future, we are here to help. About consulting
Here's the same article in video form for your convenience:
Article Series "OpenShift/OKD Course"
- Production OpenShift Cluster in 35 Minutes: First look at OKD 4 and the new OpenShift Installer
- 3 Core Features of OpenShift 4 Cluster Management: Fedora CoreOS, cri-o and MachineSet API
- How to Configure OpenShift 4 Cluster Nodes: MachineConfig Operator and CoreOS
- OpenShift 4 Troubleshooting: Your Cluster is Broken, What's Next?