Terraform Fundamentals: State Management and Dependency Graph, Creating the First Server

This is the second part of the Terraform Lightning course.
In this article, we will finally get our hands dirty and create the first cloud instance with Terraform.
But before we do so, we need to learn two concepts, that distinguish Terraform from many other tools.
State Management
The first one is the State Management.
The way most of the infrastructure as code tools work is very simple. Let's take this example written in Ansible:
- ec2_instance:
name: "my-instance"
vpc_subnet_id: subnet-5ca1ab1e
instance_type: c5.large
image_id: ami-123456
This code is going to create a new virtual server on AWS. If the instance with the name my-instance already exists, Ansible will try to update it so that it matches the code.
What happens if you remove this code? Nothing.
Once the code is gone, Ansible completely forgets that it has ever managed that instance. The server will remain unless you remove it manually or directly tell Ansible to remove it.
Another problem with this code, is that each EC2 instance has uniquely generated id which Ansible is totally unaware of.
Instead of using this id, Ansible will try to find the instance by it's name. But this name is basically just a tag called Name.
There are two problems with using Name tag as an identifier.
First, tags are not unique, which already makes them the worst type of identifier.
And second, tags are mutable. If you change the Name tag outside of Ansible playbook, Ansible will simpy try to create a new instance.
Other tools, like Chef or Puppet, work exactly the same. They do not maintain the state of resources. But Terraform does, and we will see how it manages state in a bit.
Dependecy Graph
The second fundamental concept of Terraform is a Dependecy Graph.
The regular graph is a set of nodes with and connections between then, called edges:
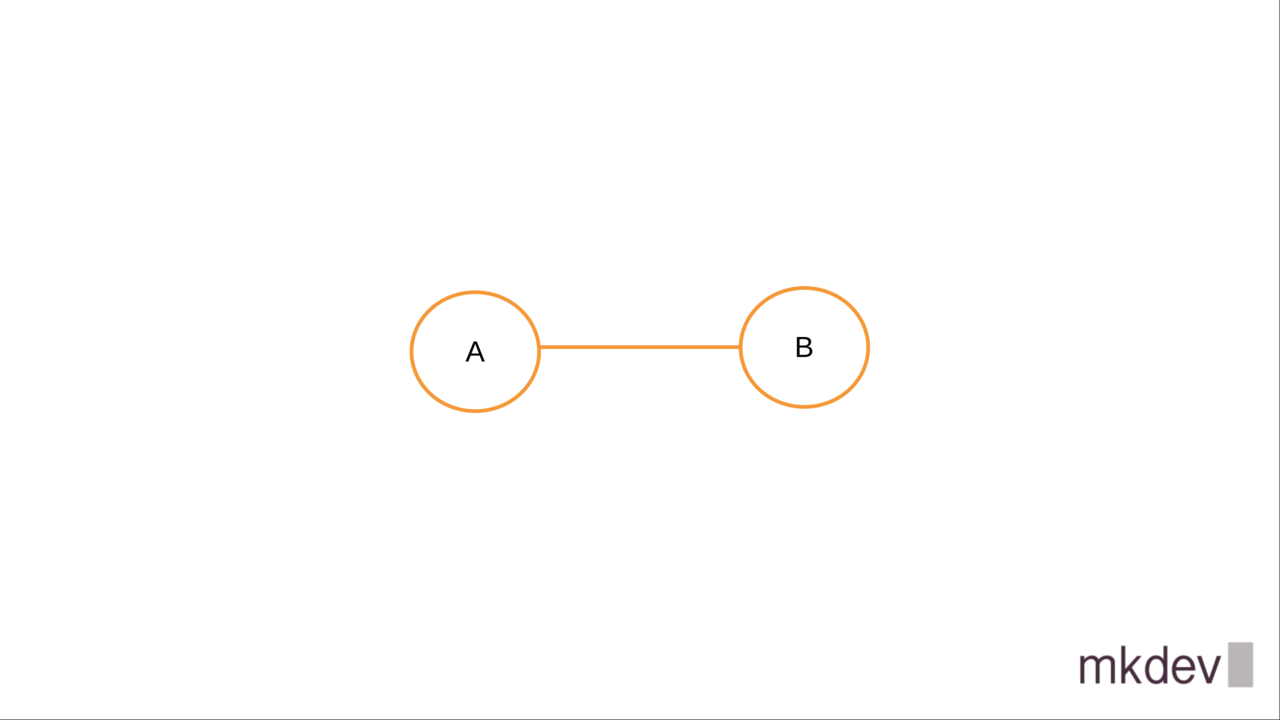
Nodes in the dependecy graph, as the name implies, have dependencies between each other, like this:
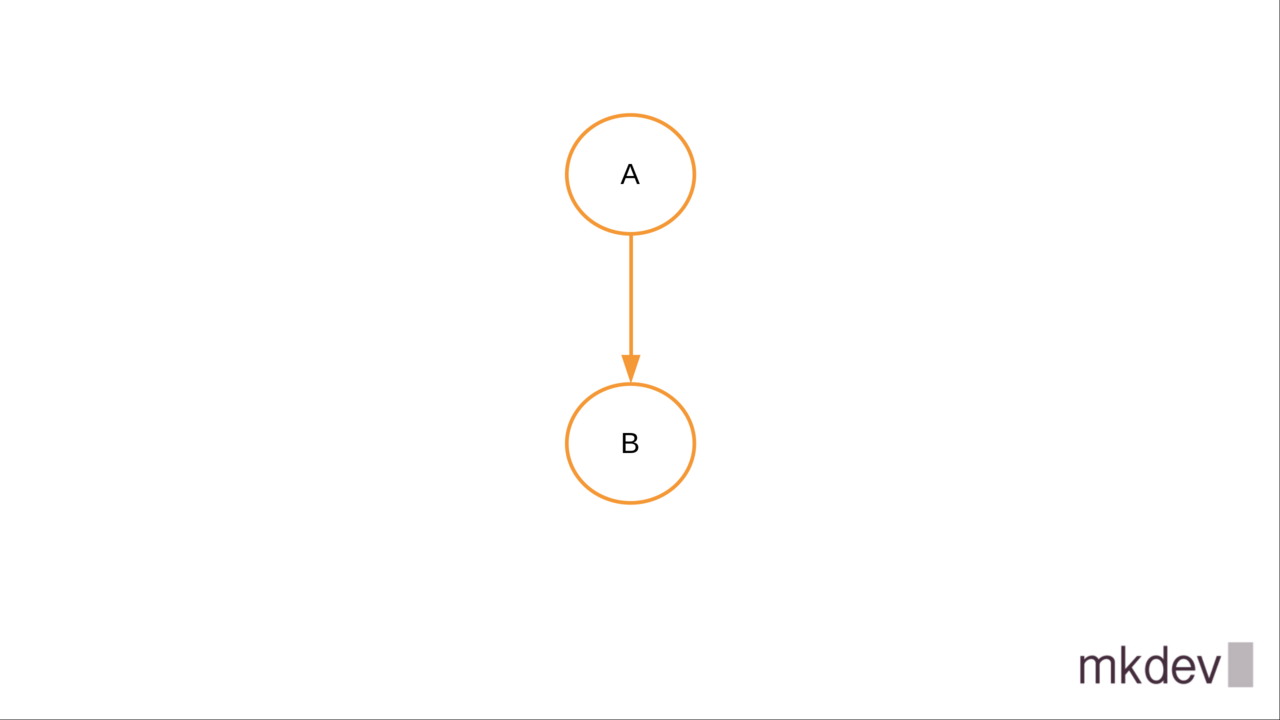
Dependency graph allows Terraform to figure out the correct order to create, update or delete resources.
When you use Terraform, you rarely have to think about how one resource depends on another. It appeared, that the good old graph theory is very handy in Infrastructure as Code world.
Both state management and depency graph are fundamental concepts in Terraform.
Creating the First Server
Let's finally write some code.
Note that I am not going to show you how to install Terraform. Installation process depends on your operating system. You are smart enough to do it without extra guidence.
The Terraform templates are written in a simple language called Hashicorp Configuration Language.
HCL has some data manipulation functions and a minimal set of data types, but it is not a feature complete programming language.
One of the best ways to learn HCL is by writing Terraform templates.
We will start writing the template by defining a "provider". Provider is responsible for communication with external APIs of a particular service or technology.
The first provider we will use is the Packet Cloud provider. Packet Cloud is a bare metal cloud provider. You can create a bare metal server just like you would create a virtual machine somewhere else.
The definition of the Packet provider is very simple, we only need to specify the auth token. Terraform will use this token when it interacts with the APIs of Packet.
Each provider has a number of resources available. Each resource corresponds to a particular infrastructure element, like a server or a load balancer.
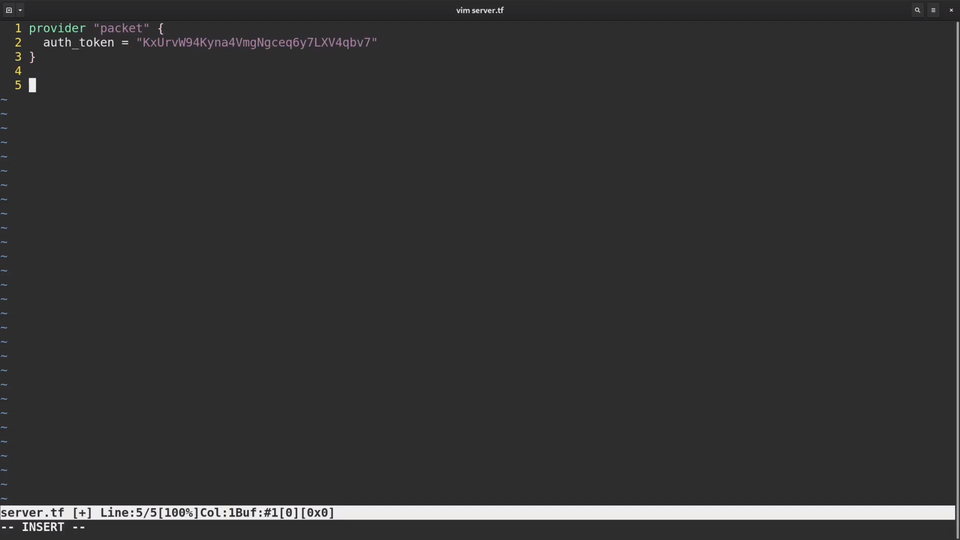
I am going to define three resources: the Packet project, the Packet Project SSH key and the Packet device.
To define a resource, we need to type a resource statement, followed by a resource type, in this case packet_project and the the unique resource name, in this case mkdev.
Inside the resource block we can define different parameters that this resource type supports. You can always look up the list of available parameters in the Terraform documentation.
For the Packet project, we will set one parameter name.
For the packet_project_ssh_key there are three parameters to define.
First is the name, also mkdev.
The second one is public_key.
I could copy and paste the complete public key contents into this template. Instead, I am going to use the file function.
This function reads the file and uses it's content as parameter value.
And the third one is project id.
Instead of typing in the actual project id, we will reference the one we are creating in this template.
To reference the attributes of resources we need to type the resource type followed by the resource name, and the attribute name.
Each resource has a lot of attributes that Terraform discovers on its own. You don't have to know the id of the project, Terraform will create it and save the id in the state.
Terraform will also recognize that it needs to create the project before the ssh key. It builds the dependency graph by checking how resources reference attributes of each other.
The last resource that I will create is called packet_device. Packet Device references both project and project ssh key ids.
Because of this reference, Terraform will first create the project and the ssh key, and only then the device. There is nothing for us to specify, dependency graph is invisible to the end user.
I also set the hostname, facilities, the plan, that is a server type, operating system and billing cycle - all of those are required for any new Packet server.
The final piece of code I am writing is the output.
Outputs are the way to fetch information from Terraform to re-use further in other automation or Terraform templates.
I need to output the public IP address of the server, so that I know how to connect to it.
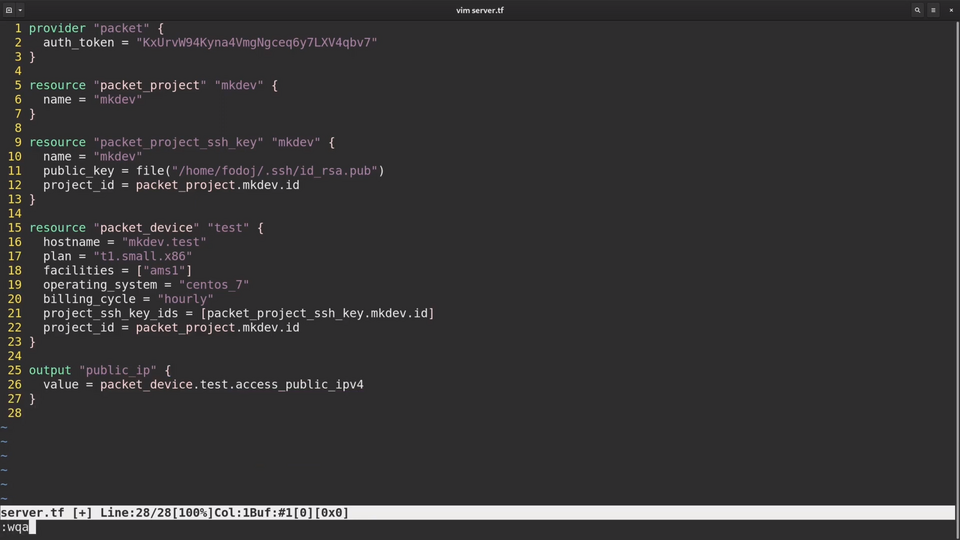
Now let's save the template and run some Terraform commands.
The first command we always need to run when create a new Terraform template is terraform init.
Terraform init will download all the providers needed for your templates. Each provider is developed and distributed independently from Terraform itself. Some of the providers are maintained by Hashicorp, some others by the community.
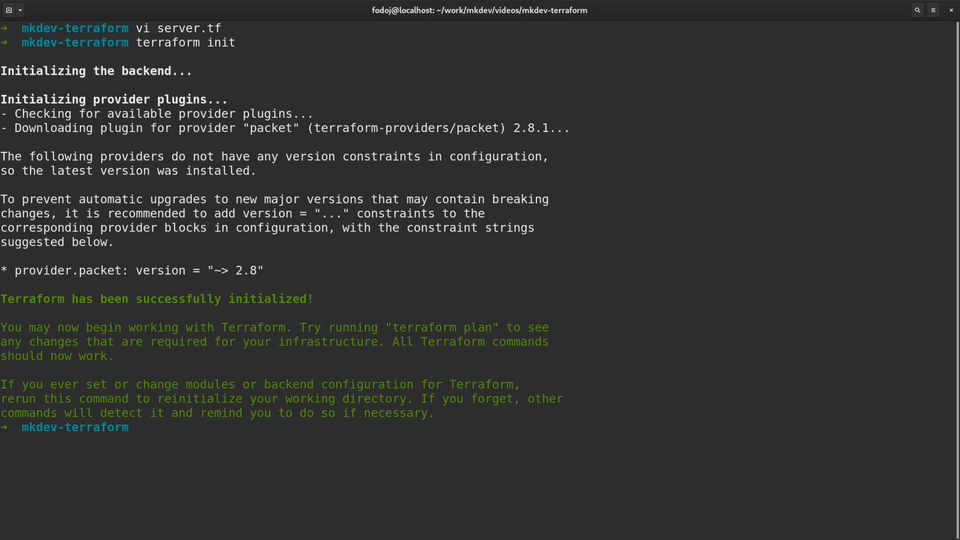
The second command we will run is terraform plan. The plan command will show us what Terraform will do if we will apply the template.
Let's examine the outpout of the plan command a little closer.
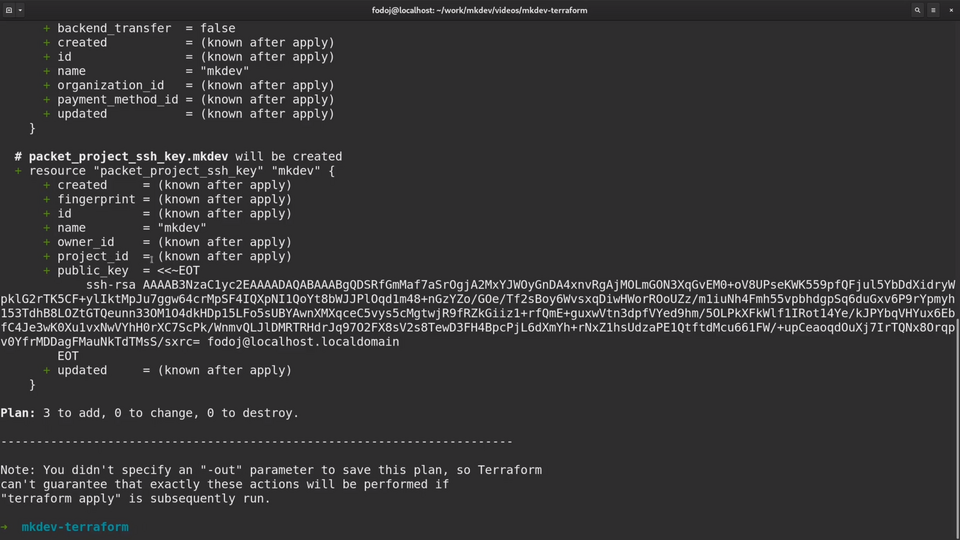
Whenever possible, you should always check the plan output before applying changes, to avoid any surprises.
Some of the parameters will be known only during the apply phase.
Terraform can not show the project id, because the project itself does not exist yet.
As for the public key, Terraform knows the value already, so it can show it the plan output.
Terraform also gives as the summary of how many resources it will add, update or delete.
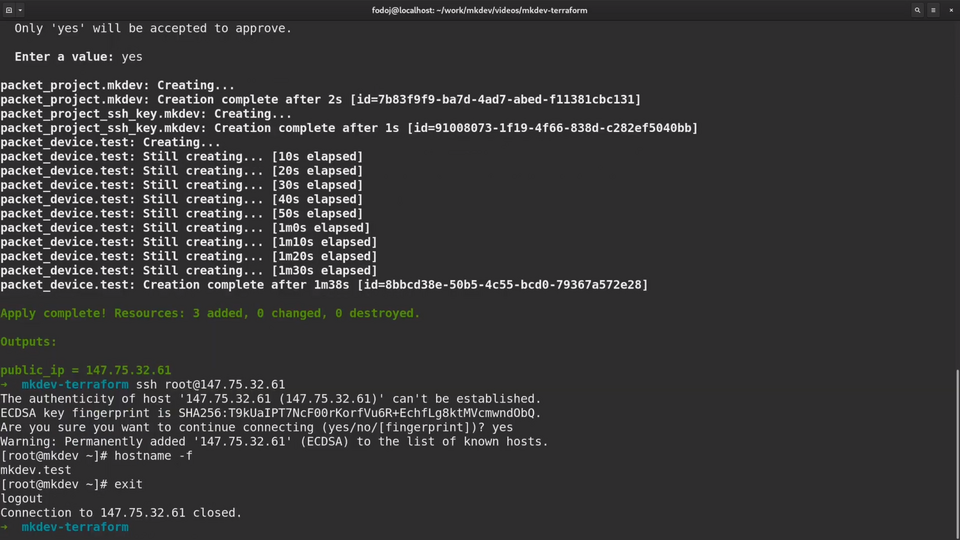
As the plan output looks fine, we can go ahead and apply the template with terraform apply command.
By default apply will first show what Terraform will do and then ask for confirmation.
I am going to confirm and see what happens.
Great, seems like all resources are provisioned.
Let me try to ssh to the newly created server. Seems to work fine!
Before we conclude this lesson, let me show you what happens if I comment out the packet_device resource from the template.
Remember, most of the other tools will not do anything.
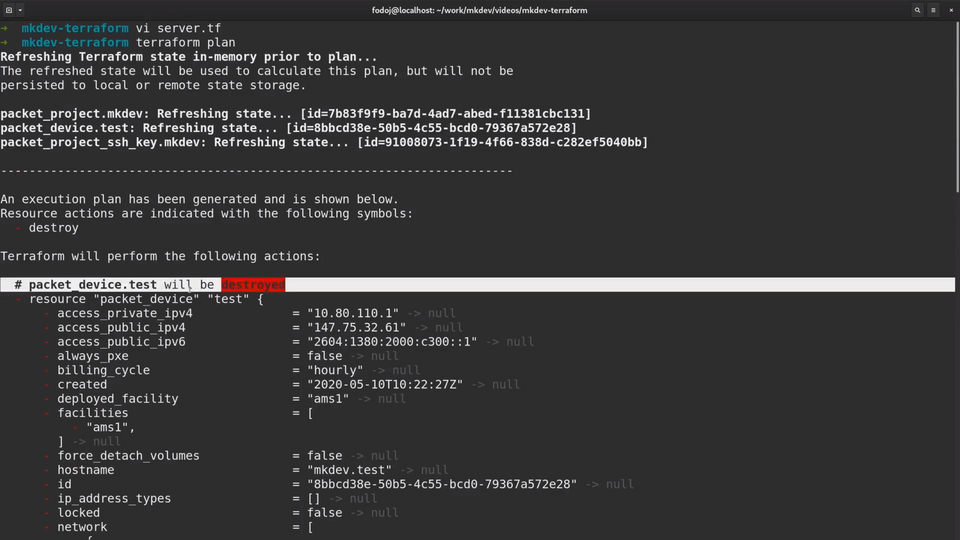
Now let me try to run the plan again.
As you see, Terraform wants to delete the actual server now. This is the result of state management we learned earlier.
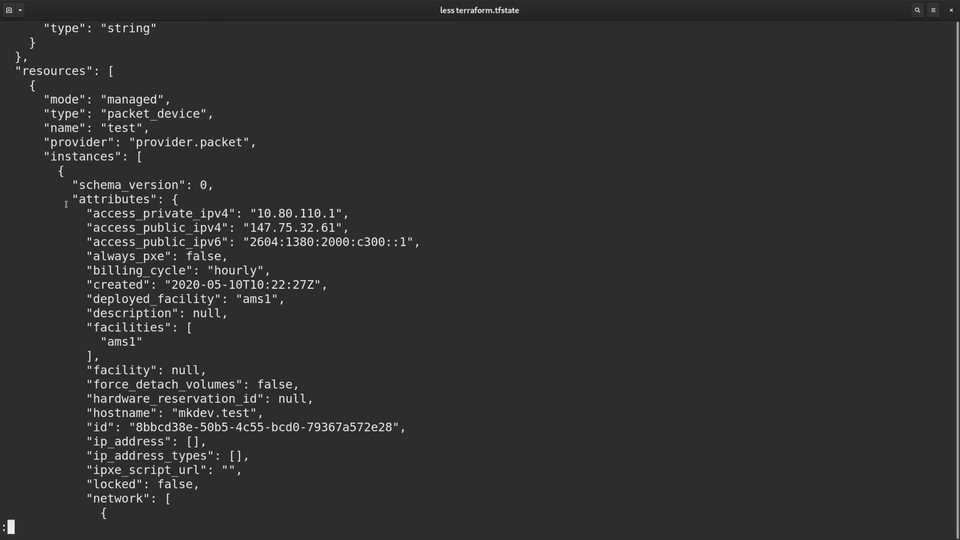
The way Terraform manages the state is my keeping a state file, which is a huge json file that stores the last known state of your infrastructure.
You can see here the server, project and the ssh key. You can also see all the attributes that Terraform pulled from the Packet API.
When Terraform runs, it compares your template with the actually existing infrastructure and with the state file.
After this comparison, it tries to bring your infrastructure to the state you defined in your template. The idea here is that your infrastructure code is the final source of truth. Terraform's goal is to make it happen.
In this case, Terraform checked the state file and found out that packet_device was defined before. It also figured out, that this packet device still exists. The next logical step is to bring your infrastruture up to date and destroy the server.
The final command for today is terraform destroy, which will delete everything we've created so far.
You should run this command after the lesson, otherwise your cloud provider will keep charging you money.
That's it for this article. In the next lesson, we are going to learn how to provide configuration to the Terraform templates.
DevOps consulting: DevOps is a cultural and technological journey. We'll be thrilled to be your guides on any part of this journey. About consulting
Here's the same article in video form for your convenience:
Article Series "Terraform Lightning Course"
- Infrastructure as Code and How Terraform Fits Into It
- Terraform Fundamentals: State Management and Dependency Graph, Creating the First Server
- Configuring Terraform Templates: Variables and Data Resources
- Terraform Tips & Tricks, Issue 1: Format, Graph and State
- Creating Multi-cloud Terraform environment with the help of remote state backends and AWS S3
- Refactor Terraform code with Modules
- Creating Kubernetes Clusters with Terraform: Learning Provisioners
- Terraform Tips & Tricks, Issue 2: Registry, Locals and Workspaces